


Ansys Fluent offers three modes of parallel processing for the discrete phase model:
Shared Memory (Linux systems only)
The Shared Memory method is suitable for computations where the machine running the Ansys Fluent host process is an adequately large, shared-memory, multiprocessor machine.
Message Passing
The Message Passing option is suitable for generic distributed memory cluster computing.
Hybrid (default)
The Hybrid option is suitable for modern multicore memory cluster computing.
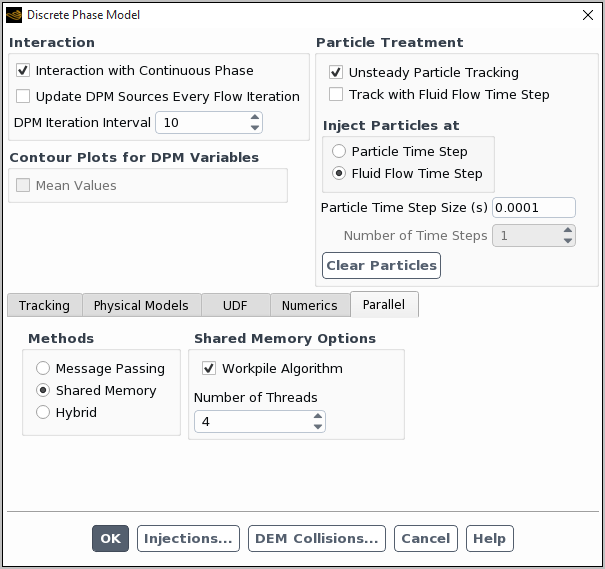
These options are found under the Parallel tab, in the Discrete Phase Model dialog box.
Important: Note the following:
When tracking particles with the DPM model in combination with any of the multiphase flow models (VOF, mixture, or Eulerian) the Shared Memory method cannot be selected. (Note that using the Message Passing or Hybrid method enables the compatibility of all multiphase flow models with the DPM model.)
Starting in version 18.2, the Shared Memory method is not compatible with serial UDFs when running in serial.
If you want to use file injections or to write a DPM summary report directly to a file, your system must meet the following requirements when either the Message Passing or Hybrid parallel DPM tracking option is selected:
The machine (for example, cluster node) running the compute-node zero process and the machine running the host process are identical or have the same operating system type (Windows or Linux)
Both machines can access the same file system through the same path specification
If these conditions are not met, you can still write a DPM summary report to a file by starting transcript, reporting the particle tracking summary to the Fluent console, and then stopping transcript. The summary report will be saved in the transcript file.
As a workaround for the DPM summary report, you can start transcript, report the particle tracking summary to the Fluent console, and stop transcript. The summary report will be saved in the transcript file
The Shared Memory option (Figure 24.74: The Shared Memory Option with Workpile Algorithm Enabled) is implemented using POSIX Threads (pthreads) based on a shared-memory model. Once the Shared Memory option is enabled, you can then select along with it the Workpile Algorithm and specify the Number of Threads. By default, the Number of Threads is equal to the number of compute nodes specified for the parallel computation. You can modify this value based on the computational requirements of the particle calculations. If, for example, the particle calculations require more computation than the flow calculation, you can increase the Number of Threads (up to the number of available processors) to improve performance. When using the Shared Memory option, the particle calculations are entirely managed by the Ansys Fluent host process. You must make sure that the machine executing the host process has enough memory to accommodate the entire mesh.
Important: Note that the Shared Memory option on Windows-based architectures only provides serial tracking on the host, since the Workpile Algorithm is not available due to lack of POSIX Threads on these platforms.
Important: Note that the Workpile Algorithm option is not available with the wall film boundary condition. It will be disabled automatically when choosing to simulate a wall film on a wall.
The Message Passing option enables cluster computing and also works on shared-memory machines. With this option enabled, the compute node processes perform the particle work on their local partitions. Particle migration to other compute nodes is implemented using message passing primitives. There are no special requirements for the host machine. By default, pathline displays are computed in serial on the host node. Pathline displays may be computed in parallel on distributed memory systems if the Message Passing parallel option is selected in the Discrete Phase Model dialog box.
The Hybrid option combines Message Passing and OpenMP for a dynamic load balancing without migration of cells, enables multicore cluster computing, and also works on shared-memory machines. With this option enabled, the compute node processes perform the particle calculations on their local partitions. OpenMP threads will be spawned, and the number of threads in each Ansys Fluent node process is based on the evaluation of the particle load on the current machine. The maximum number of threads on each machine can be controlled using the Thread Control dialog box (see Controlling the Threads for details). The default value is the number of Ansys Fluent node processes on each machine. Particle migration to other compute nodes is implemented using message passing primitives. There are no special requirements for the host machine. Pathline displays are computed by default in serial on the host node. Pathline displays may also be computed in parallel on distributed memory systems if the Message Passing option is selected from the Methods list. For a list of limitations that exist with Hybrid parallel method, see Limitations on Using the Hybrid Parallel Method.
Note that for fully coupled flow simulations, the Hybrid tracking option may cause slightly different results between runs. The reason for this difference is the non-commutative nature of summations performed with finite-precision floating-point numbers. This becomes more pronounced with the accumulation of particle source term contributions. The order in which particles are tracked and deposit their sources is determined by the execution order of the OpenMP threads. This order varies from run to run, which leads to small changes in the accumulated DPM source terms. Due to the non-linear nature of many physical processes, these differences in the DPM sources may increase and become noticeable as variations in the simulation results.
To avoid the variations between runs, you can issue the following text command:
define/models/dpm/parallel/fix-source-term-accumulation-order?
Note that using this option may lead to an execution time increase.
When using the Hybrid method, you may optionally enable Use DPM Domain under Hybrid Options. This option can provide substantially improved load balancing, and thus scalability, at the expense of additional memory overhead. When Use DPM Domain is enabled, particle tracking is performed on a separate domain from the root computational domain. Flow and DPM variables are copied between the domains as part of the solution process. By using a separate domain, and thus partitioning strategy, for particle tracking the continuous and discrete phase loads are balanced independently. This allows the load to be shared more equally among the machines regardless of how particles are distributed throughout the computational domain. This is especially beneficial for simulations with non-uniform particle distributions over the computational domain. For limitations associated with the Use DPM Domain option, see Limitations on Using the Hybrid Parallel Method. With this option, you may also want to use the following text commands:
parallel→partition→set→dpm-load-balancingThis text command enables dynamic load balancing. You will be prompted to define a load imbalance threshold (that is, a percentage above which load balancing will occur), as well as the interval of DPM iterations at which you would like load balancing attempted. It is recommended that you retain the default values, as these are appropriate for a wide range of cases.
define→models→dpm→parallel→expert→partition-method-hybrid-2domainThis enables a partitioning method that is more granular and can yield faster calculations (especially for cases that are running on a low to moderate number of processors).
You may seamlessly switch among the Shared Memory option, the Message Passing option, and the Hybrid option at any time during the Ansys Fluent session.
In addition to performing general parallel processing of the Discrete Phase Model, you have the option of implementing DPM-specific user-defined functions in parallel Ansys Fluent. For more information about the parallelization of DPM UDFs, see Parallelization of Discrete Phase Model (DPM) UDFs in the Fluent Customization Manual.
When using the Message Passing or the Hybrid option you can make use of Ansys Fluent’s automated load balancing capability by giving an appropriate weight to the particle steps in each cell. In this case the number of particle steps in each partition is considered in the load balancing procedure. Further details can be found in Using the Partitioning and Load Balancing Dialog Box.