


Ansys Fluent's solver contains three types of executable: Cortex, host, and compute node (or
simply "node" for short). When Ansys Fluent runs, an instance of Cortex starts,
followed by one host and n compute nodes, thereby giving a total of
n+2 running processes. For this reason, it is necessary when
running in parallel (and recommended when running in serial) that you make sure that your
function will successfully execute as a host and a node process. At first it may appear that
you should write two different versions of your UDF: one for host, and one for node. Good
programming practice, however, would suggest that you write a single UDF that, when compiled,
can execute on the two versions. This process is referred to in this manual as "parallelizing"
a serial UDF (that is, a UDF that does not account for the separate processes). You can do
this by adding special macros as well as compiler directives to your UDF, as described below.
Compiler directives, (such as #if RP_NODE,
RP_HOST) and their negated forms, direct the compiler to include
only portions of the function that apply to a particular process, and ignore the rest (see
Compiler Directives).
A general rule of thumb is that your serial UDF must be "parallelized" if it performs an operation that is dependent on sending or receiving data from another compute node (or the host) or uses a macro type that was introduced after Ansys Fluent version 18.2 (which are not guaranteed to be supported in serial UDFs). Some types of operations that require parallelization of serial source code when used with multiple nodes include the following:
Reading and Writing Files
Global Reductions
Global Sums
Global Minimums and Maximums
Global Logicals
Certain Loops over Cells and Faces
Displaying Messages on a Console
Printing to a Host or Node Process
After the source code for your "parallelized" UDF has been written, it can be compiled using the same methods for serial UDFs. Instructions for compiling UDFs can be found in Compiling UDFs.
The DPM model can be used for the following parallel options:
Shared Memory
Message Passing
When you are using a DPM-specific UDF (see Discrete Phase Model (DPM) DEFINE Macros), it will
be executed on the machine that is in charge of the considered particle, based on the
above-mentioned parallel options. Since all fluid variables needed for DPM models are held
in data structures of the tracked particles, no special care is needed when using DPM UDFs
in parallel Ansys Fluent with the following two exceptions.
Firstly, when you are writing to a sampling output file using the
DEFINE_DPM_OUTPUT macro, you are not allowed to use the C
function fprintf. Instead new functions
par_fprintf and par_fprintf_head are
provided to enable the parallel file writing. Each compute node writes its information to a
separate temporary file. These individual files are put together and sorted into the final
output file by Ansys Fluent. The new functions can be used with the same parameter lists as the
C function fprintf with the stipulation that the sorting of the
files by Ansys Fluent requires the specification of an extended parameter list. For details on
the use of these macros refer to The par_fprintf_head and par_fprintf
Functions and
DEFINE_DPM_OUTPUT
.
The second exception arises when storing information about particles. In the case of
parallel simulations, you must use particle-specific user variables as they can be accessed
with the macros TP_USER_REAL(tp, i)
(tp being of the type
Tracked_Particle *) and
PP_USER_REAL(p, i) (p being of the
type Particle *). Only this information is carried with the
particles across partition boundaries, while other local or global variables are not carried
across partition boundaries.
Note that if you need to access other data, such as cell values, then for the parallel
options except Shared Memory you will have access to all fluid and solver variables. When
you choose the Shared Memory option, however, you will have access only to the variables
defined in the macros SV_DPM_LIST and
SV_DPMS_LIST. These macros are defined in the file
dpm.h.
This section contains macros that you can use to parallelize your serial UDF. Where applicable, definitions for these macros can be found in the referenced header file (such as para.h).
- 7.3.2.1. Compiler Directives
- 7.3.2.2. Communicating Between the Host and Node Processes
- 7.3.2.3. Predicates
- 7.3.2.4. Global Reduction Macros
- 7.3.2.5. Looping Macros
- 7.3.2.6. Cell and Face Partition ID Macros
- 7.3.2.7. Message Displaying Macros
- 7.3.2.8. Message Passing Macros
- 7.3.2.9. Macros for Exchanging Data Between Compute Nodes
When converting a UDF to run in parallel, some parts of the function may need to be
done by the host and some by the compute nodes. This distinction is made when the UDF is
compiled. By using Ansys Fluent-provided compiler directives, you can specify portions of your
function to be assigned to the host or to the compute nodes. The UDF that you write will
be written as a single file for the host and node versions, but different parts of the
function will be compiled to generate different versions of the dynamically linked shared
object file libudf.so (libudf.dll on
Windows). Print tasks, for example, may be assigned exclusively to the host, while a task
such as computing the total volume of a complete mesh will be assigned to the compute
nodes. Since most operations are executed by either the host or compute nodes, negated
forms of compiler directives are more commonly used.
Note that the primary purpose of the host is to interpret commands from Cortex and to
pass those commands (and data) to compute node-0 for distribution. Since the host does not
contain mesh data, you will need to be careful not to include the host in any calculations
that could, for example result in a division by zero. In this case, you will need to
direct the compiler to ignore the host when it is performing mesh-related calculations, by
wrapping those operations around the #if !RP_HOST directive. For
example, suppose that your UDF will compute the total area of a face thread, and then use
that total area to compute a flux. If you do not exclude the host from these operations,
the total area on the host will be zero and a floating point exception will occur when the
function attempts to divide by zero to obtain the flux.
Example
#if !RP_HOST avg_pres = total_pres_a / total_area; /* if you do not exclude the host
this operation will result in a division by zero and error!
Remember that host has no data so its total will be zero.*/
#endif
You will need to use the #if !RP_NODE directive when you want
to exclude compute nodes from operations for which they do not have data.
Below is a list of parallel compiler directives and what they do:
/**********************************************************************/
/* Compiler Directives */
/**********************************************************************/
#if RP_HOST
/* only host process is involved */
#endif
#if RP_NODE
/* only compute nodes are involved */
#endif
/*********************************************************************/
/* Negated forms that are more commonly used */
/*********************************************************************/
#if !RP_HOST
/* only compute nodes are involved */
#endif
#if !RP_NODE
/* only host process is involved */
#endif
The following simple UDF shows the use of compiler directives. The adjust function is
used to define a function called where_am_i. This function
queries to determine which type of process is executing and then displays a message on
that computed node’s monitor.
Example
/*****************************************************
Simple UDF that uses compiler directives
*****************************************************/
#include "udf.h"
DEFINE_ADJUST(where_am_i, domain)
{
#if RP_HOST
Message("I am in the host process\n");
#endif /* RP_HOST */
#if RP_NODE
Message("I am in the node process with ID %d\n",myid);
/* myid is a global variable which is set to the multiport ID for
each node */
#endif /* RP_NODE */
}
This simple allocation of functionality between the different types of processes is
useful in a limited number of practical situations. For example, you may want to display a
message on the compute nodes when a particular computation is being run (by using
RP_NODE or !RP_HOST). Or, you can also
choose to designate the host process to display messages (by using
RP_HOST or !RP_NODE). Usually you want
messages written only once by the host process. Simple messages such as "Running the
Adjust Function" are straightforward. Alternatively, you may want to collect data from all
the nodes and print the total once, from the host. To perform this type of operation your
UDF will need some form of communication between processes. The most common mode of
communication is between the host and the node processes.
There are two sets of similar macros that can be used to send data between the host
and the compute nodes: host_to_node_type_num and
node_to_host_type_num.
To send data from the host process to all the node processes (indirectly via compute node-0), macros of the following form is used:
host_to_node_type_num(val_1,val_2,...,val_num);
where ‘num’ is the number of variables that will be passed in the argument list and ‘type’ is the data type of the variables that will be passed. The maximum number of variables that can be passed is 7. Arrays and strings can also be passed from host to nodes, one at a time, as shown in the examples below.
For information about transferring a file from the host to a node, see Reading Files in Parallel.
Examples
/* integer and real variables passed from host to nodes */
host_to_node_int_1(count);
host_to_node_real_7(len1, len2, width1, width2, breadth1, breadth2, vol);
/* string and array variables passed from host to nodes */
char wall_name[]="wall-17";
int thread_ids[10] = {1,29,5,32,18,2,55,21,72,14};
host_to_node_string(wall_name,8); /* remember terminating NUL character */
host_to_node_int(thread_ids,10);
Note that these host_to_node communication macros do not
need to be "protected" by compiler directives for parallel UDFs, because all of these
macros automatically do the following:
send the variable value if compiled as the host version
receive and then set the local variable if compiled as a compute node version
The most common use for this set of macros is to pass parameters or boundary conditions from the host to the nodes processes. See the example UDF in Parallel UDF Example for a demonstration of usage.
To send data from compute node-0 to the host process, use macros of the form:
node_to_host_type_num(val_1,val_2,...,val_num);
where ‘num’ is the number of variables that will be passed in the argument list and ‘type’ is the data type of the variables that will be passed. The maximum number of variables that can be passed is 7. Arrays and strings can also be passed from host to nodes, one at a time, as shown in the examples below.
Note that unlike the host_to_node macros, which pass data
from the host process to all of the compute nodes (indirectly via
compute node-0), node_to_host macros pass data
only from compute node-0 to the host.
Examples
/* integer and real variables passed from compute node-0 to host */ node_to_host_int_1(count); node_to_host_real_7(len1, len2, width1, width2, breadth1, breadth2, vol); /* string and array variables passed from compute node-0 to host */ char *string; int string_length; real vel[ND_ND]; node_to_host_string(string,string_length); node_to_host_real(vel,ND_ND);
node_to_host macros do not need to be protected by compiler
directives (such as #if RP_NODE) since they automatically do
the following:
send the variable value if the node is compute node-0 and the function is compiled as a node version
do nothing if the function is compiled as a node version, but the node is not compute node-0
receive and set variables if the function is compiled as the host version
The most common usage for this set of macros is to pass global reduction results from compute node-0 to the host process. In cases where the value that is to be passed is computed by all of the compute nodes, there must be some sort of collection (such as a summation) of the data from all the compute nodes onto compute node-0 before the single collected (summed) value can be sent. Refer to the example UDF in Parallel UDF Example for a demonstration of usage and Global Reduction Macros for a full list of global reduction operations.
There are a number of macros available in parallel Ansys Fluent that expand to logical
tests. These logical macros, referred to as "predicates", are denoted by the suffix
P and can be used as test conditions in your UDF. The following
predicates return TRUE if the condition in the parenthesis is
met.
/* predicate definitions from para.h header file */ # define MULTIPLE_COMPUTE_NODE_P (compute_node_count > 1) # define ONE_COMPUTE_NODE_P (compute_node_count == 1) # define ZERO_COMPUTE_NODE_P (compute_node_count == 0)
There are a number of predicates that allow you to test the identity of the node
process in your UDF, using the compute node ID. A compute node’s ID is stored as
the global integer variable myid (see Process Identification). Each of the macros listed below tests certain
conditions of myid for a process. For example, the predicate
I_AM_NODE_ZERO_P compares the value of
myid with the compute node-0 ID and returns
TRUE when they are the same.
I_AM_NODE_SAME_P(n), on the other hand, compares the compute
node ID that is passed in n with myid.
When the two IDs are the same, the function returns TRUE. Node ID
predicates are often used in conditional-if statements in UDFs.
/* predicate definitions from para.h header file */ # define I_AM_NODE_HOST_P (myid == host) # define I_AM_NODE_ZERO_P (myid == node_zero) # define I_AM_NODE_ONE_P (myid == node_one) # define I_AM_NODE_LAST_P (myid == node_last) # define I_AM_NODE_SAME_P(n) (myid == (n)) # define I_AM_NODE_LESS_P(n) (myid < (n)) # define I_AM_NODE_MORE_P(n) (myid > (n))
Recall that from Cells and Faces in a Partitioned Mesh, a face
may appear in one or two partitions but in order that summation operations do not count it
twice, it is officially allocated to only one of the partitions. The tests above are used
with the neighboring cell’s partition ID to determine if it belongs to the current
partition. The convention that is used is that the smaller-numbered compute node is
assigned as the "principal" compute node for that face.
PRINCIPAL_FACE_P returns TRUE if the
face is located on its principal compute node. The macro can be used as a test condition
when you want to perform a global sum on faces and some of the faces are partition
boundary faces. Below is the definition of PRINCIPAL_FACE_P from
para.h. See Cells and Faces in a Partitioned Mesh for more information about
PRINCIPAL_FACE_P.
/* predicate definitions from para.h header file */ # define PRINCIPAL_FACE_P(f,t) (!TWO_CELL_FACE_P(f,t) || \ PRINCIPAL_TWO_CELL_FACE_P(f,t)) # define PRINCIPAL_TWO_CELL_FACE_P(f,t) \ (!(I_AM_NODE_MORE_P(C_PART(F_C0(f,t),THREAD_T0(t))) || \ I_AM_NODE_MORE_P(C_PART(F_C1(f,t),THREAD_T1(t)))))
Global reduction operations are those that collect data from all of the compute nodes,
and reduce the data to a single value, or an array of values. These include operations
such as global summations, global maximums and minimums, and global logicals. These macros
begin with the prefix PRF_G and are defined in
prf.h. Global summation macros are identified by the suffix
SUM, global maximums by HIGH, and
global minimums by LOW. The suffixes AND
and OR identify global logicals.
The variable data types for each macro are identified in the macro name, where
R denotes real data types, I denotes
integers, and L denotes logicals. For example, the macro
PRF_GISUM finds the summation of integers over the compute
nodes.
Each of the global reduction macros discussed in the following sections has two
different versions: one takes a single variable argument, while the other takes a variable
array. Macros with a 1 (one) appended to the end of the name take
one argument, and return a single variable as the global reduction result. For example,
the macro PRF_GIHIGH1(x) expands to a function that takes one
argument x and computes the maximum of the variable
x among all of the compute nodes, and returns it. The result
can then be assigned to another variable (such as y), as shown in
the following example.
Example: Global Reduction Variable Macro
{
int y;
int x = myid;
y = PRF_GIHIGH1(x); /* y now contains the same number (compute_node_count
- 1) on all the nodes */
}
Macros without a 1 suffix, on the other
hand, compute global reduction variable arrays. These macros take three arguments:
x, N, and
iwork where x is an array,
N is the number of elements in the array, and
iwork is an array that is of the same type and size as
x which is needed for temporary storage. Macros of this type
are passed an array x and the elements of array
x are filled with the new result after returning from the
function. For example, the macro PRF_GIHIGH(x,N,iwork) expands to
a function that computes the maximum of each element of the array
x over all the compute nodes, uses the array
iwork for temporary storage, and modifies array
x by replacing each element with its resulting global maximum.
The function does not return a value.
Example: Global Reduction Variable Array Macro
{
real x[N], iwork[N];
/* The elements of x are set in the working array here and will
have different values on each compute node.
In this case, x[0] could be the maximum cell temperature of all
the cells on the compute node. x[1] the maximum pressure, x[2]
the maximum density, etc.
*/
PRF_GRHIGH(x,N,iwork); /* The maximum value for each value over
all the compute nodes is found here */
/* The elements of x on each compute node now hold the same
maximum values over all the compute nodes for temperature,
pressure, density, etc. */
}
Macros that can be used to compute global sums of variables are identified by the
suffix SUM. PRF_GISUM1 and
PRF_GISUM compute the global sum of
integer variables and integer
variable arrays, respectively.
PRF_GRSUM1(x) computes the global sum of a
real variable x across all compute
nodes. The global sum is of type float when running a single
precision version of Ansys Fluent and type double when running the
double precision version. Alternatively, PRF_GRSUM(x,N,iwork)
computes the global sum of a float variable array for single
precision and double when running double precision.
|
Global Summations | |
|---|---|
|
Macro |
Action |
|
|
Returns sum of integer |
|
|
Sets |
|
|
Returns sum of |
|
|
Sets |
Macros that can be used to compute global maximums and minimums of variables are
identified by the suffixes HIGH and
LOW, respectively. PRF_GIHIGH1 and
PRF_GIHIGH compute the global maximum of
integer variables and integer
variable arrays, respectively.
PRF_GRHIGH1(x) computes the global maximum of a
real variable x across all compute
nodes. The value of the global maximum is of type float when
running the single precision version of Ansys Fluent and type
double when running the double precision version.
PRF_GRHIGH(x,N,iwork) computes the global maximum of a
real variable array, similar to the description of
PRF_GRSUM(x,N,iwork) on the previous page. The same naming
convention used for PRF_GHIGH macros applies to
PRF_GLOW.
|
Global Maximums | |
|---|---|
|
Macro |
Action |
|
|
Returns maximum of integer |
|
|
Sets |
|
|
Returns maximums of |
|
|
Sets |
|
Global Minimums | |
|---|---|
|
Macro |
Action |
|
|
Returns minimum of integer |
|
|
Sets |
|
|
Returns minimum of |
|
|
Sets |
Macros that can be used to compute global logical ANDs and logical ORs are
identified by the suffixes AND and OR,
respectively. PRF_GBOR1(x) computes the global logical OR of
variable x across all compute nodes.
PRF_GBOR(x,N,iwork) computes the global logical OR of
variable array x. The elements of x
are set to TRUE if any of the corresponding elements on the
compute nodes are TRUE.
By contrast, PRF_GBOR(x) computes the global logical AND
across all compute nodes and PRF_GBOR(x,N,iwork) computes the
global logical AND of variable array x. The elements of
x are set to TRUE if all of the
corresponding elements on the compute nodes are TRUE.
The PRF_GBOR1(x) and PRF_GBAND1(x)
macros expect a cxboolean argument x
and return a cxboolean result value. The
PRF_GBOR(x, N, iwork) and PRF_GBAND(x, N,
iwork) macros expect cxboolean array (pointer)
arguments x and iwork.
|
Global Logicals | |
|---|---|
|
Macro |
Action |
|
|
|
|
|
|
|
|
|
|
|
|
Similar macros containing "I" instead of "B" in their names are available for the
int data type.
PRF_GSYNC() can be used when you want to globally
synchronize compute nodes before proceeding with the next operation. When you insert a
PRF_GSYNC macro in your UDF, no commands beyond it will
execute until the preceding commands in the source code have been completed on all of
the compute nodes. Synchronization may also be useful when debugging your
function.
There are different looping macros for interior and exterior cells and faces available for parallel coding.
A partitioned mesh in parallel Ansys Fluent is made up of interior cells and exterior cells (see Figure 7.6: Partitioned Mesh: Cells). There is a set of cell-looping macros you can use to loop over interior cells only, exterior cells only, or both interior and exterior cells.
The macro begin,end_c_loop_int loops over interior cells in
a partitioned mesh (Figure 7.11: Looping Over Interior Cells in a Partitioned Mesh Using
begin,end_c_loop_int (indicated by the green cells)) and is
identified by the suffix int. It contains a
begin and end statement, and between
these statements, operations can be performed on each of the thread’s interior
cells in turn. The macro is passed a cell index c and a cell
thread pointer tc.
begin_c_loop_int(c, tc)
{
} end_c_loop_int(c, tc)
Figure 7.11: Looping Over Interior Cells in a Partitioned Mesh Using
begin,end_c_loop_int (indicated by the green cells)
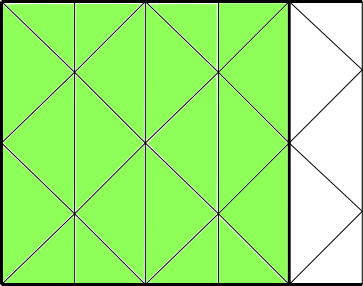
Example
real total_volume = 0.0;
begin_c_loop_int(c,tc)
{
/* C_VOLUME gets the cell volume and accumulates it. The end
result will be the total volume of each compute node’s
respective mesh */
total_volume += C_VOLUME(c,tc);
} end_c_loop_int(c,tc)
There are three macros to loop over exterior cells in a partitioned mesh (Figure 7.12: Looping Over Exterior Cells in a Partitioned Mesh Using
begin,end_c_loop_[re]ext (indicated by the green cells)).
begin,end_c_loop_rextloops over regular exterior cells.begin,end_c_loop_eextloops over extended exterior cells.begin,end_c_loop_extloops over both regular and extended exterior cells.
Each macro contains a begin and
end statement, and between these statements, operations can
be performed on each of the thread’s exterior cells in turn. The macro is passed
a cell index c and cell thread pointer
tc. In most situations, there is no need to use the exterior
cell loop macros. They are only provided for convenience if you come across a special
need in your UDF.
begin_c_loop_ext(c, tc)
{
} end_c_loop_ext(c,tc)
Figure 7.12: Looping Over Exterior Cells in a Partitioned Mesh Using
begin,end_c_loop_[re]ext (indicated by the green cells)
![Looping Over Exterior Cells in a Partitioned Mesh Using begin,end_c_loop_[re]ext (indicated by the green cells)](graphics/g_flu_udf_udf_begin_end_c_loop_ext.png)
There are two macros to loop over interior and some or all exterior cells in a
partitioned mesh (Figure 7.13: Looping Over Both Interior and Exterior Cells in a Partitioned Mesh Using
begin,end_c_loop_int_ext).
begin,end_c_looploops over interior and regular exterior cells.begin,end_c_loop_int_extloops over interior and all exterior cells.
Each macro contains a begin and
end statement, and between these statements, operations can
be performed on each of the thread’s interior and exterior cells in turn. The
macro is passed a cell index c and a cell thread pointer
tc.
begin_c_loop(c, tc)
{
} end_c_loop(c ,tc)
Figure 7.13: Looping Over Both Interior and Exterior Cells in a Partitioned Mesh Using
begin,end_c_loop_int_ext
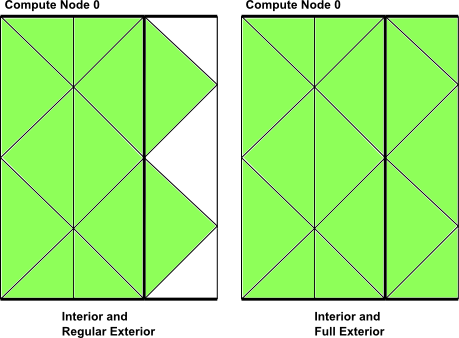
Example
real temp;
begin_c_loop(c,tc)
{
/* get cell temperature, compute temperature function and store
result in user-defined memory, location index 0. */
temp = C_T(c,tc);
C_UDMI(c,tc,0) = (temp - tmin) / (tmax - tmin);
/* assumes a valid tmax and tmin has already been computed */
} end_c_loop(c,tc)
For the purpose of discussing parallel Ansys Fluent, faces can be categorized into two types: interior faces and boundary zone faces (Figure 7.7: Partitioned Mesh: Faces). Partition boundary faces are interior faces that lie on the partition boundary of a compute node’s mesh.
begin,end_f_loop is a face looping macro available in
parallel Ansys Fluent that loops over all interior and boundary zone faces in a compute
node. The macro begin,end_f_loop contains a
begin and end statement, and between
these statements, operations can be performed on each of the faces of the thread. The
macro is passed a face index f and face thread pointer
tf.
begin_f_loop(f, tf)
{
} end_f_loop(f,tf)
Important:
begin_f_loop_int and
begin_f_loop_ext are looping macros that loop around
interior and exterior faces in a compute node, respectively. The
_int form is equivalent to
begin_c_loop_int. Although these macros exist, they do not
have a practical application in UDFs and should not be used.
Recall that partition boundary faces lie on the boundary between two adjacent
compute nodes and are represented on both nodes. Therefore, there are some computations
(such as summations) when a partition boundary face will get counted twice in a face
loop. This can be corrected by testing whether the current node is a face’s
principal compute node inside your face looping macro, using
PRINCIPAL_FACE_P. This is shown in the example below. See
Cells and Faces in a Partitioned Mesh for details.
Example
begin_f_loop(f,tf)
/* each compute node checks whether or not it is the principal compute
node with respect to the given face and thread */
if PRINCIPAL_FACE_P(f,tf)
/* face is on the principal compute node, so get the area and pressure
vectors, and compute the total area and pressure for the thread
from the magnitudes */
{
F_AREA(area,f,tf);
total_area += NV_MAG(area);
total_pres_a += NV_MAG(area)*F_P(f,tf);
} end_f_loop(f,tf)
total_area = PRF_GRSUM1(total_area);
total_pres_a = PRF_GRSUM1(total_pres_a);
In general, cells and faces have a partition ID that is numbered from
0 to n-1, where
n is the number of compute nodes. The partition IDs of cells
and faces are stored in the variables C_PART and
F_PART, respectively. C_PART(c,tc)
stores the integer partition ID of a cell and F_PART(f,tf) stores
the integer partition ID of a face.
Note that myid can be used in conjunction with the partition
ID, since the partition ID of an exterior cell is the ID of the neighboring compute
node.
For interior cells, the partition ID is the same as the compute node ID. For
exterior cells, the compute node ID and the partition ID are different. For example, in
a parallel system with two compute nodes (0 and 1), the exterior cells of compute node-0
have a partition ID of 1, and the exterior cells of compute
node-1 have a partition ID of 0 (Figure 7.14: Partition Ids for Cells and Faces in a Compute Node).
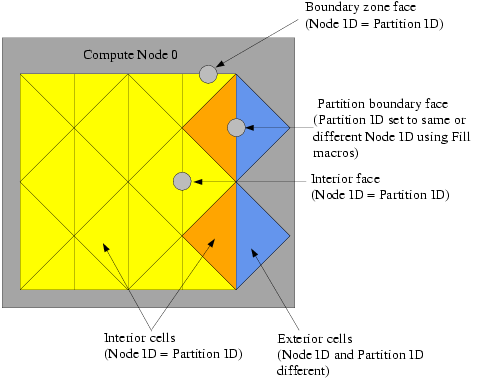
For interior faces and boundary zone faces, the partition ID is the same as the
compute node ID. The partition ID of a partition boundary face, however, can be either
the same as the compute node, or it can be the ID of the adjacent node, depending on
what values F_PART is filled with (Figure 7.14: Partition Ids for Cells and Faces in a Compute Node). Recall that an exterior cell of a
compute node has only partition boundary faces; the other faces of the cell belong to
the adjacent compute node. Therefore, depending on the computation you want to do with
your UDF, you may want to fill the partition boundary face with the same partition ID as
the compute node (using Fill_Face_Part_With_Same) or with
different IDs (using Fill_Face_Part_With_Different). Face
partition IDs will need to be filled before you can access them with the
F_PART macro. There is rarely a need for face partition IDs
in parallel UDFs.
You can direct Ansys Fluent to display messages on a host or node
process using the Message utility. To do this, simply use a
conditional if statement and the appropriate compiler directive
(such as #if RP_NODE) to select the process(es) you want the
message to come from. This is demonstrated in the following example:
Example
#if RP_NODE
Message("Total Area Before Summing %f\n",total\_area);
#endif /* RP_NODE */
In this example, the message will be sent by the compute nodes. (It will not be sent by the host.)
Message0 is a specialized form of the
Message utility. Message0 will send
messages from compute node-0 only and is ignored on the other compute nodes, without
having to use a compiler directive.
Example
/* Let Compute Node-0 display messages */
Message0("Total volume = %f\n",total_volume);
High-level communication macros of the form node_to_host...
and host_to_node... that are described in Communicating Between the Host and Node Processes are typically used when you want to send
data from the host to all of the compute nodes, or from node-0 to the host. You cannot,
however, use these high-level macros when you need to pass data between compute nodes, or
pass data from all of the compute nodes to compute node-0. In these cases, you can use
special message passing macros described in this section.
Note that the higher-level communication macros expand to functions that perform a
number of lower-level message passing operations which send sections of data as single
arrays from one process to another process. These lower-level message passing macros can
be easily identified in the macro name by the characters SEND and
RECV. Macros that are used to send data to processes have the
prefix PRF_CSEND, whereas macros that are used to receive data
from processes have the prefix PRF_CRECV. Data that is to be sent
or received can belong to the following data types: character
(CHAR), integer (INT),
REAL and logical (BOOLEAN).
BOOLEAN variables are TRUE or
FALSE. REAL variables are assigned as
float data types when running a single precision version of
Ansys Fluent and double when running double precision. Message
passing macros are defined in the prf.h header file and are listed
below.
/* message passing macros */ PRF_CSEND_CHAR(to, buffer, nelem, tag) PRF_CRECV_CHAR (from, buffer, nelem, tag) PRF_CSEND_INT(to, buffer, nelem, tag) PRF_CRECV_INT(from, buffer, nelem, tag) PRF_CSEND_REAL(to, buffer, nelem, tag) PRF_CRECV_REAL(from, buffer, nelem, tag) PRF_CSEND_BOOLEAN(to, buffer, nelem, tag) PRF_CRECV_BOOLEAN(from, buffer, nelem, tag)
There are four arguments to the message-passing macros. For ‘send’ messages:
tois the node ID of the process that data is being sent to.bufferis the name of an array of the appropriate type that will be sent.nelemis the number of elements in the array.tagis a user-defined message tag. The tag convention is to usemyidwhen sending messages.
For ‘receive’ messages:
fromis the ID of the sending node.bufferis the name of an array of the appropriate type that will be received.nelemis the number of elements in the array.tagis the ID of the sending node, as the convention is to have thetagargument the same as thefromargument (that is, the first argument) for receive messages.
Note that if variables that are to be sent or received are defined in your function as
real variables, then you can use the message passing macros
with the _REAL suffix. The compiler will then substitute
PRF_CSEND_DOUBLE or PRF_CRECV_DOUBLE
if you are running double precision and PRF_CSEND_FLOAT or
PRF_CRECV_FLOAT, for single precision.
Because message-passing macros are low-level macros, you will need to make sure that
when a message is sent from a node process, a corresponding receiving macro appears in the
receiving-node process. Note that your UDF cannot directly send messages from a compute
node (other than 0) to the host using message-passing macros. They can send messages
indirectly to the host through compute node-0. For example, if you want your parallel UDF
to send data from all of the compute nodes to the host for postprocessing purposes, the
data will first have to be passed from each compute node to compute node-0, and then from
compute node-0 to the host. In the case where the compute node processes send a message to
compute node-0, compute node-0 must have a loop to receive the N
messages from the N nodes.
Below is an example of a compiled parallel UDF that utilizes message passing macros
PRF_CSEND and PRF_CRECV. Refer to the
comments (*/) in the code, for details about the function.
Example: Message Passing
#include "udf.h"
#define WALLID 3
DEFINE_ON_DEMAND(face_p_list)
{
#if !RP_HOST /* Host will do nothing in this udf. */
face_t f;
Thread *tf;
Domain *domain;
real *p_array;
real x[ND_ND], (*x_array)[ND_ND];
int n_faces, i, j;
domain=Get_Domain(1); /* Each Node will be able to access
its part of the domain */
tf=Lookup_Thread(domain, WALLID); /* Get the thread from the domain */
/* The number of faces of the thread on nodes 1,2... needs to be sent
to compute node-0 so it knows the size of the arrays to receive
from each */
n_faces=THREAD_N_ELEMENTS_INT(tf);
/* No need to check for Principal Faces as this UDF
will be used for boundary zones only */
if(! I_AM_NODE_ZERO_P) /* Nodes 1,2... send the number of faces */
{
PRF_CSEND_INT(node_zero, &n_faces, 1, myid);
}
/* Allocating memory for arrays on each node */
p_array=(real *)malloc(n_faces*sizeof(real));
x_array=(real (*)[ND_ND])malloc(ND_ND*n_faces*sizeof(real));
begin_f_loop(f, tf)
/* Loop over interior faces in the thread, filling p_array
with face pressure and x_array with centroid */
{
p_array[f] = F_P(f, tf);
F_CENTROID(x_array[f], f, tf);
}
end_f_loop(f, tf)
/* Send data from node 1,2, ... to node 0 */
Message0("\nstart\n");
if(! I_AM_NODE_ZERO_P) /* Only SEND data from nodes 1,2... */
{
PRF_CSEND_REAL(node_zero, p_array, n_faces, myid);
PRF_CSEND_REAL(node_zero, x_array[0], ND_ND*n_faces, myid);
}
else
{/* Node-0 has its own data,
so list it out first */
Message0("\n\nList of Pressures...\n");
for(j=0; j<n_faces; j++)
/* n_faces is currently node-0 value */
{
# if RP_3D
Message0("%12.4e %12.4e %12.4e %12.4e\n",
x_array[j][0], x_array[j][1], x_array[j][2], p_array[j]);
# else /* 2D */
Message0("%12.4e %12.4e %12.4e\n",
x_array[j][0], x_array[j][1], p_array[j]);
# endif
}
}
/* Node-0 must now RECV data from the other nodes and list that too */
if(I_AM_NODE_ZERO_P)
{
compute_node_loop_not_zero(i)
/* See para.h for definition of this loop */
{
PRF_CRECV_INT(i, &n_faces, 1, i);
/* n_faces now value for node-i */
/* Reallocate memory for arrays for node-i */
p_array=(real *)realloc(p_array, n_faces*sizeof(real));
x_array=(real(*)[ND_ND])realloc(x_array,ND_ND*n_faces*sizeof(real));
/* Receive data */
PRF_CRECV_REAL(i, p_array, n_faces, i);
PRF_CRECV_REAL(i, x_array[0], ND_ND*n_faces, i);
for(j=0; j<n_faces; j++)
{
# if RP_3D
Message0("%12.4e %12.4e %12.4e %12.4e\n",
x_array[j][0], x_array[j][1], x_array[j][2], p_array[j]);
# else /* 2D */
Message0("%12.4e %12.4e %12.4e\n",
x_array[j][0], x_array[j][1], p_array[j]);
# endif
}
}
}
free(p_array); /* Each array has to be freed before function exit */
free(x_array);
#endif /* ! RP_HOST */
}
EXCHANGE_SVAR_MESSAGE,
EXCHANGE_SVAR_MESSAGE_EXT, and
EXCHANGE_SVAR_FACE_MESSAGE can be used to exchange storage
variables (SV_...) between compute nodes.
EXCHANGE_SVAR_MESSAGE and
EXCHANGE_SVAR_MESSAGE_EXT exchange cell data between compute
nodes, while EXCHANGE_SVAR_FACE_MESSAGE exchanges face data.
EXCHANGE_SVAR_MESSAGE is used to exchange data over regular
exterior cells, while EXCHANGE_SVAR_MESSAGE_EXT is used to
exchange data over regular and extended exterior cells. Note that compute nodes are
‘virtually’ synchronized when an EXCHANGE macro is
used; receiving compute nodes wait for data to be sent, before continuing.
/* Compute Node Exchange Macros */ EXCHANGE_SVAR_FACE_MESSAGE(domain, (SV_P, SV_NULL)); EXCHANGE_SVAR_MESSAGE(domain, (SV_P, SV_NULL)); EXCHANGE_SVAR_MESSAGE_EXT(domain, (SV_P, SV_NULL));
EXCHANGE_SVAR_FACE_MESSAGE() is rarely needed in UDFs. You
can exchange multiple storage variables between compute nodes. Storage variable names are
separated by commas in the argument list and the list is ended by
SV_NULL. For example, EXCHANGE_SVAR_MESSAGE(domain,
(SV_P, SV_T, SV_NULL)) is used to exchange cell pressure and temperature
variables. You can determine a storage variable name from the header file that contains
the variable’s definition statement. For example, suppose you want to exchange the
cell pressure (C_P) with an adjacent compute node. You can look
at the header file that contains the definition of C_P
(mem.h) and determine that the storage variable for cell
pressure is SV_P. You will need to pass the storage variable to
the exchange macro.
The macro PRINCIPAL_FACE_P can be used
only in compiled UDFs.
PRF_GRSUM1 and similar global reduction macros (Global Reduction Macros) cannot be used within macros such as
DEFINE_SOURCE and DEFINE_PROPERTY UDFs,
which are generally called for each cell (or face) and thus are called a different number of
times on each compute node. As a workaround, you can use macros that are called only once on
each node, such as DEFINE_ADJUST,
DEFINE_ON_DEMAND, and
DEFINE_EXECUTE_AT_END UDFs. For example, you could write a
DEFINE_ADJUST UDF that calculates a global sum value in the
adjust function, and then save the variable in user-defined memory. You can subsequently
retrieve the stored variable from user-defined memory and use it inside a
DEFINE_SOURCE UDF. This is demonstrated below.
In the following example, the spark volume is calculated in the
DEFINE_ADJUST function and the value is stored in user-defined
memory using C_UDMI. The volume is then retrieved from user-defined
memory and used in the DEFINE_SOURCE UDF.
#include "udf.h"
/* These variables will be passed between the ADJUST and SOURCE UDFs */
static real spark_center[ND_ND] = {ND_VEC(20.0e-3, 1.0e-3, 0.0)};
static real spark_start_angle = 0.0, spark_end_angle = 0.0;
static real spark_energy_source = 0.0;
static real spark_radius = 0.0;
static real crank_angle = 0.0;
DEFINE_ADJUST(adjust, domain)
{
#if !RP_HOST
const int FLUID_CHAMBER_ID = 2;
real cen[ND_ND], dis[ND_ND];
real crank_start_angle;
real spark_duration, spark_energy;
real spark_volume;
real rpm;
cell_t c;
Thread *ct;
rpm = RP_Get_Real("dynamesh/in-cyn/crank-rpm");
crank_start_angle = RP_Get_Real("dynamesh/in-cyn/crank-start-angle");
spark_start_angle = RP_Get_Real("spark/start-ca");
spark_duration = RP_Get_Real("spark/duration");
spark_radius = RP_Get_Real("spark/radius");
spark_energy = RP_Get_Real("spark/energy");
/* Set the global angle variables [deg] here for use in the SOURCE UDF */
crank_angle = crank_start_angle + (rpm * CURRENT_TIME * 6.0);
spark_end_angle = spark_start_angle + (rpm * spark_duration * 6.0);
ct = Lookup_Thread(domain, FLUID_CHAMBER_ID);
spark_volume = 0.0;
begin_c_loop_int(c, ct)
{
C_CENTROID(cen, c, ct);
NV_VV(dis,=,cen,-,spark_center);
if (NV_MAG(dis) < spark_radius)
{
spark_volume += C_VOLUME(c, ct);
}
}
end_c_loop_int(c, ct)
spark_volume = PRF_GRSUM1(spark_volume);
spark_energy_source = spark_energy/(spark_duration*spark_volume);
Message0("\nSpark energy source = %g [W/m3].\n", spark_energy_source);
#endif
}
DEFINE_SOURCE(energy_source, c, ct, dS, eqn)
{
/* Don't need to mark with #if !RP_HOST as DEFINE_SOURCE is only executed
on nodes as indicated by the arguments "c" and "ct" */
real cen[ND_ND], dis[ND_ND];
if((crank_angle >= spark_start_angle) &&
(crank_angle < spark_end_angle))
{
C_CENTROID(cen, c, ct);
NV_VV(dis,=,cen,-,spark_center);
if (NV_MAG(dis) < spark_radius)
{
return spark_energy_source;
}
}
/* Cell is not in spark zone or within time of spark discharge */
return 0.0;
}
Important: Interpreted UDFs cannot be used with an Infiniband interconnect. The compiled UDF approach should be used in this case.
Each process in parallel Ansys Fluent has a unique integer identifier that is stored as the
global variable myid. When you use myid
in your parallel UDF, it will return the integer ID of the current compute node
(including the host). The host process has an ID of host(=999999)
and is stored as the global variable host. Compute node-0 has an ID
of 0 and is assigned to the global variable
node_zero. Below is a list of global variables in parallel
Ansys Fluent.
Global Variables in Parallel Ansys Fluent
int node_zero = 0; int node_host = 999999; int node_one = 1; int node_last; /* returns the id of the last compute node */ int compute_node_count; /* returns the number of compute nodes */ int myid; /* returns the id of the current compute node (and host) */
myid is commonly used in conditional-if statements in parallel
UDF code. Below is some sample code that uses the global variable
myid. In this example, the total number of faces in a face thread
is first computed by accumulation. Then, if myid is not compute
node-0, the number of faces is passed from all of the compute nodes to compute node-0 using
the message passing macro PRF_CSEND_INT. (See Message Passing Macros for details on
PRF_CSEND_INT.)
Example: Usage of myid
int noface=0;
begin_f_loop(f, tf) /* loops over faces in a face thread and
computes number of faces */
{
noface++;
}
end_f_loop(f, tf)
/* Pass the number of faces from node 1,2, ... to node 0 */
#if RP_NODE if(myid!=node_zero)
{
PRF_CSEND_INT(node_zero, &noface, 1, myid);
}
#endif
The following is an example of a serial UDF that has been
parallelized, so that it can run on any version of Ansys Fluent (host, node). Explanations for
the various changes from the simple serial version are provided in the /*
comments */ and discussed below. The UDF, named
face_av, is defined using an adjust function, computes a global
sum of pressure on a specific face zone, and computes its area average.
Example: Global Summation of Pressure on a Face Zone and its Area Average Computation
#include "udf.h"
DEFINE_ADJUST(face_av,domain)
{
/* Variables used by host, node versions */
int surface_thread_id=0;
real total_area=0.0;
real total_force=0.0;
/* "Parallelized" Sections */
#if !RP_HOST /* Compile this section for computing processes only since
these variables are not available on the host */
Thread* thread;
face_t face;
real area[ND_ND];
#endif /* !RP_HOST */
/* Get the value of the thread ID from a user-defined Scheme variable */
#if !RP_NODE
surface_thread_id = RP_Get_Integer("user/pres_av/thread-id");
Message("\nCalculating on Thread # %d\n",surface_thread_id);
#endif /* !RP_NODE */
/* To set up this user Scheme variable in cortex type */
/* (rp-var-define 'user/pres_av/thread-id 2 'integer #f) */
/* After set up you can change it to another thread's ID using : */
/* (rpsetvar 'user/pres_av/thread-id 7) */
/* Send the ID value to all the nodes */
host_to_node_int_1(surface_thread_id);
#if RP_NODE Message("\nNode %d is calculating on thread # %d\n",myid,
surface_thread_id);
#endif /* RP_NODE */
#if !RP_HOST
/* thread is only used on compute processes */
thread = Lookup_Thread(domain,surface_thread_id);
begin_f_loop(face,thread)
/* If this is the node to which face "officially" belongs,*/
/* get the area vector and pressure and increment */
/* the total area and total force values for this node */
if (PRINCIPAL_FACE_P(face,thread))
{
F_AREA(area,face,thread);
total_area += NV_MAG(area);
total_force += NV_MAG(area)*F_P(face,thread);
}
end_f_loop(face,thread)
Message("Total Area Before Summing %f\n",total_area);
Message("Total Normal Force Before Summing %f\n",total_force);
# if RP_NODE /* Perform node synchronized actions here */
total_area = PRF_GRSUM1(total_area);
total_force = PRF_GRSUM1(total_force);
# endif /* RP_NODE */
#endif /* !RP_HOST */
/* Pass the node's total area and pressure to the Host for averaging */
node_to_host_real_2(total_area,total_force);
#if !RP_NODE
Message("Total Area After Summing: %f (m2)\n",total_area);
Message("Total Normal Force After Summing %f (N)\n",total_force);
Message("Average pressure on Surface %d is %f (Pa)\n",
surface_thread_id,(total_force/total_area));
#endif /* !RP_NODE */
}
The function begins by initializing the variables
surface_thread_id, total_area, and
total_force for all processes. This is done because the variables
are used by the host and node processes. The compute nodes use the variables for computation
purposes and the host uses them for message-passing and displaying purposes. Next, the
preprocessor is directed to compile thread,
face, and area variables only on the
node versions (and not the host), since faces and threads are only defined in the node
versions of Ansys Fluent. (Note that in general, the host will ignore these statements since its
face and cell data are zero, but it is good programming practice to exclude the host. See
Macros for Parallel UDFs for details on compiler directives.)
Next, a user-defined Scheme variable named
user/pres_av/thread-id is obtained by the host process using the
RP_Get_Integer utility (see Scheme Macros), and is assigned to the variable
surface_thread_id. (Note that this user-defined Scheme variable was
previously set up in Cortex and assigned a value of 2 by typing the
text commands shown in the comments.) After a Scheme-based variable is set up for the thread
ID, it can be easily changed to another thread ID from the text interface, without the
burden of modifying the source code and recompiling the UDF. Since the host communicates
with Cortex and the nodes are not aware of Scheme variables, it is essential to direct the
compiler to exclude the nodes from compiling them using #if
!RP_NODE. Failure to do this will result in a compile error.
The surface_thread_id is then passed from the host to compute
node-0 using the host_to_node macro. Compute node-0, in turn,
automatically distributes the variable to the other compute nodes. The node processes are
directed to loop over all faces in the thread associated with the
surface_thread_id, using #if !RP_HOST,
and compute the total area and total force. Since the host does not contain any thread data,
it will ignore these statements if you do not direct the compiler, but it is good
programming practice to do so. The macro PRINCIPAL_FACE_P is used
to ensure that faces at partition boundaries are not counted twice (see Cells and Faces in a Partitioned Mesh). The nodes display the total area
and force on the monitors (using the Message utility) before the
global summation. PRF_GRSUM1 (Global Reduction Macros) is a global summation macro that is used to
compute the total area and force of all the compute nodes. These operations are directed for
the compute nodes using #if RP_NODE.