


Whether you start Ansys Fluent either from the Linux or Windows command line with no arguments, from the Windows Programs menu, or from the Windows desktop, Fluent Launcher will appear (for details, see Starting Ansys Fluent Using Fluent Launcher in the Getting Started part of this manual), where you can select the mesh or case file that you would like to start with, as well as other options (for example, whether you want a single-precision or double-precision calculation).
Parallel calculation options can be set up by specifying a number of Solver Processes greater than 1 under Parallel (Local Machine) in the Fluent Launcher.
The Parallel Settings tab allows you to specify settings for running Ansys Fluent in parallel.
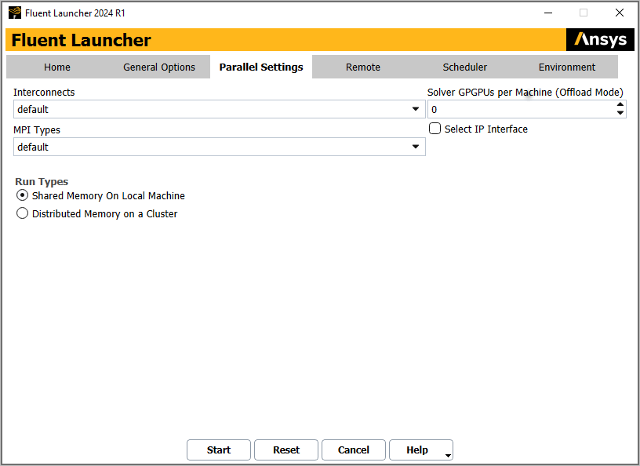
If your machines are equipped with appropriate General Purpose Graphical Processing Units (GPGPUs) you can indicate that these should be used in offload mode for Algebraic Multigrid (AMG) solver acceleration and/or Discrete Ordinates (DO) solver acceleration by setting the Solver GPGPUs per Machine (Offload Mode). Note that the number of solver processes per machine must be the same for all machines and that the number of processes per machine must be evenly divisible into the value you specify for Solver GPGPUs per Machine (Offload Mode). That is, for nprocs solver processes running on M machines using ngpgpus GPGPUS per machine:
Table 43.1: Examples for GPGPUs per Machine presents several examples illustrating the relationship between number of machines, number of solver processes, and GPGPUs per machine.
Table 43.1: Examples for GPGPUs per Machine
Example 1 Example 2 Example 3 Number of Machines ( M)1 4 4 Number of Solver Processes ( nprocs)4 12 22 Valid values for GPGPUs per Machine ( ngpgpus)1, 2, 4 1, 3 ngpgpuswill be ignored and GPGPU acceleration will be disabled (Mdoes not evenly dividenprocs)See Using General Purpose Graphics Processing Units (GPGPUs) With the Algebraic Multigrid (AMG) Solver and/or Accelerating Discrete Ordinates (DO) Radiation Calculations for more information about using GPGPU acceleration.
Specify the interconnect in the Interconnects drop-down list. The default setting is recommended. For a symmetric multi-processor (SMP) system, the default setting uses shared memory for communication. On Windows, the best available interconnect is automatically used.
(Linux only) If you prefer to select a specific interconnect, you can choose ethernet, ethernet.efa, or infiniband. For more information about these interconnects, see Table 43.5: Supported Interconnects for Linux Platforms (Per Platform), Table 43.6: Available MPIs for Linux Platforms, and Table 43.7: Supported MPIs for Linux Architectures (Per Interconnect).
Specify the type of message passing interface (MPI) you require for the parallel computations in the MPI Types field. The list of MPI types varies depending on the selected release and the selected architecture. There are several options, based on the operating system of the parallel cluster. For more information about the available MPI types, see Table 43.2: Supported Interconnects for the Windows Platform - Table 43.3: Available MPIs for Windows Platforms.
Important: It is your responsibility to make sure the interconnects and the MPI types are compatible. If incompatible inputs are used, Fluent Launcher resorts to using the default values.
Specify the type of parallel calculation under Run Types:
Select Shared Memory on Local Machine if the parallel calculations are performed by sharing memory allocations on your local machine.
Select Distributed Memory on a Cluster if the parallel calculations will be distributed among several machines.
You can select Machine Names and enter the machine names directly into the text field as a list. Machine names can be separated either by a comma or a space. This is not recommended for a long list of machine names.
Alternatively, you can select File Containing Machine Names to specify a hosts file (a file that contains the machine names), or you can use the
 button to browse for a hosts file. If you do not browse for the
hosts file and it is not located in the Working Directory you
specified in the Home tab, you must enter the full pathname to
the file. On Linux, you may also need to enter the full pathname in some scheduler and
custom-scripted scenarios; you will know this is the case if Fluent prints the
following error message:
button to browse for a hosts file. If you do not browse for the
hosts file and it is not located in the Working Directory you
specified in the Home tab, you must enter the full pathname to
the file. On Linux, you may also need to enter the full pathname in some scheduler and
custom-scripted scenarios; you will know this is the case if Fluent prints the
following error message:Error: file "hosts.txt" does not exist!
To edit an existing hosts file, click the
 button.
button.By default, Fluent allocates ranks to machines in contiguous blocks, where the block sizes are as equal as possible. You can control the per machine block allocation size using the
machineX:Y convention in the hosts specification, where Y is the process block count for machineX. The process assignment will cycle through the machine list until all processes are allocated in specified blocks. A fully round-robin assignment of processes can be achieved by setting the machine block allocation sizes to 1 (for example,machine1:1,machine2:1, and so on).
Enable the Select IP Interface option and make a selection from the drop-down list that appears if you would like to specify the IP interface to be used by the host process. This is equivalent to the
-host_ip=host:ipcommand line option. An example of when you might use this option is when you are using distributed memory on multiple machines and your security software is dropping the active socket connections used by Ansys Fluent (resulting in the following message in the console:The fl process could not be started.); while it is preferable to avoid this by creating an exception for Ansys Fluent in your security software, you could instead select a suitable IP interface.For certain platforms, enable the Use Job Scheduler option in the Scheduler tab of Fluent Launcher if the parallel calculations are to be performed using a designated Job Scheduler (for details, see Setting Parallel Scheduler Options in Fluent Launcher).

For additional information, see the following sections:
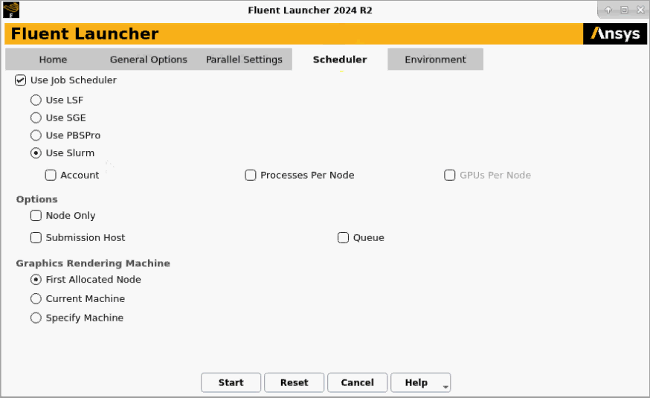
The Scheduler tab allows you to specify settings for running Ansys Fluent with various job schedulers (for example, the Microsoft Job Scheduler for Windows, or LSF, SGE, PBS Professional, and Slurm on Linux).
For Windows 64-bit, with MSMPI, you can specify that you want to use the Job Scheduler by enabling Use Job Scheduler in the Scheduler tab. Once enabled, you can then enter a machine name in the Compute Cluster Head Node Name text field. If you are running Ansys Fluent on the head node, then you can keep the field empty. This option translates into the proper parallel command line syntax for using the Microsoft Job Scheduler (for details, see Starting Parallel Ansys Fluent with the Microsoft Job Scheduler).
If you want Ansys Fluent to start after the necessary resources have been allocated by the Scheduler, then select the Start When Resources are Available check box.
For Linux (or when the Use Remote Linux Nodes option is enabled in the Remote tab on Windows), enable Use Job Scheduler in the Scheduler tab to use one of four available job schedulers.
Select Use LSF to use the LSF load management system with or without checkpointing. If you enable Use Checkpointing, then you can specify a checkpointing directory by enabling Checkpointing Directory and selecting it from the list below. By default, the current working directory is used. In addition, you can enable Automatic Checkpoint with Setting of Period and specify a numerical value for the frequency of automatic checkpointing in the field below.
For more information, see Setting Job Scheduler Options When Running on Remote Linux Machines or Part I: Running Fluent Under LSF.
Select Use SGE to use the SGE load management system. You can choose to make a selection for the SGE qmaster, as well as the SGE Queue, or the SGE pe. Alternatively, with Linux you can enable the Use SGE settings check box and specify the location and name of the SGE configuration file.
For more information, see Setting Job Scheduler Options When Running on Remote Linux Machines or Part III: Running Fluent Under SGE.
Select Use PBSPro to use the PBS Professional load management system.
For more information, see Setting Job Scheduler Options When Running on Remote Linux Machines or Part II: Running Fluent Under PBS Professional.
Select Use Slurm to use the Slurm load management system. You can enable the Account option and make a selection from the list below. If you want to set the number of node processes per cluster node (rather than leaving it to the cluster configuration), you can enable the Processes Per Node option and enter a value in the field below. If you enabled the Native GPU Solver option in the Home tab, you can enable the GPUs Per Node option and enter a value in the field below.
For more information, see Setting Job Scheduler Options When Running on Remote Linux Machines or Part IV: Running Fluent Under Slurm.
You have the following options under Options:
Enable the Node Only option to specify that Cortex and host processes are launched before the job submission and that only the parallel node processes are submitted to the scheduler.
For SGE and PBS Professional, you can enable the Tight Coupling option to enable a job-scheduler-supported native remote node access mechanism in Linux. For details about the MPI / job scheduler combinations that are supported for this tight coupling, see Running Fluent Using a Load Manager.
For LSF, PBS Professional, and Slurm, you can the enable the Submission Host option and make a selection from the drop-down list to specify the submission host name for submitting the job. This is needed if the machine you are using to run the launcher cannot submit jobs to the job scheduler.
For LSF, PBS Professional, and Slurm, you can enable the Queue option and make a selection from the drop-down list to specify the queue name or (for Slurm) partition name.
If you experience poor graphics performance when using a job scheduler in Linux, you may be able to improve performance by changing the machine on which Cortex (the process that manages the graphical user interface and graphics) is running. The Graphics Rendering Machine list provides the following options:
Select First Allocated Node if you want Cortex to run on the same machine as that used for compute node 0. Note that this is not available if you have enabled the Node Only option.
Select Current Machine if you want Cortex to run on the same machine used to start Fluent Launcher.
Select Specify Machine if you want Cortex to run on a specified machine, which you select from the drop-down list below.
Note that if you enable the Tight Coupling option, it is not used if the Cortex process is launched after the job submission (which is the default when not using the Node Only option) and is run outside of the scheduler environment by using Current Machine or Specify Machine.
Important: (Exceed onDemand Only) If you select the Current Machine or
Specify Machine, you must also set the
CORTEX_PRE=ssrun environment variable to specify the server side
rendering to ensure accelerated graphics performance.
For example:
CORTEX_PRE=/opt/Exceed_connection_server_13.8_64/bin/ssrun.
Note that the path to ssrun may be different for your
specific environment.
Note: Some Linux scheduler options available from the command line are not available in Fluent Launcher, such as specifying the scheduler job submission machine name or setting the scheduler standard error file or standard output file. For details, see Scheduler Options.
For Windows, you also have the ability to run in batch mode (using the Run in Batch Mode check box) when you provide a journal file that exits Ansys Fluent at the end of the run.
For machines running Microsoft HPC Pack 2008 or newer, you also have the following options to choose from:
Job Template allows you to create a custom submission policy to define the job parameters for an application. The cluster administrator can use job templates to manage job submission and optimize cluster usage.
Node Group allows you to specify a collection of nodes. Cluster administrators can create groups and assign nodes to one or more groups.
Processor Unit allows you to choose the following:
Core refers to a single computing unit in a machine. For example, a quad-core processor has 4 cores.
Socket refers to a set of tightly integrated cores as on a single chip. Machines often have 2 or more sockets, each socket with multiple cores. A dual CPU, hexcore processor, for example, having a total of 12 cores.
Node refers to a named host, that is, a single machine used as part of a cluster. Typical clusters range from a few to tens, hundreds, or sometimes thousands of machines.
The Remote tab allows you to specify settings for running Ansys Fluent parallel simulations on Linux machines (either in serial or on parallel Linux clusters) via the Windows interface.
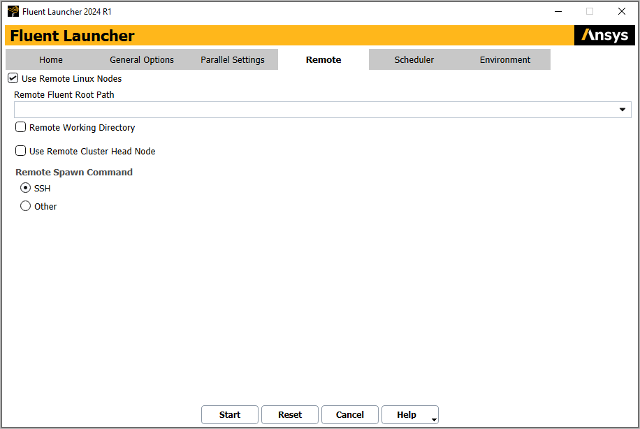
To access remote 64-bit Linux clusters for your parallel calculation, enable the
Use Remote Linux Nodes option. You can then specify the remote Ansys Fluent
Linux installation root path in the Remote Fluent Root Path field (for
example, path/ansys_inc/v242/fluent,
where path is the Linux machine directory in which you installed
Ansys Fluent). The Remote Working Directory option and field allows you to
specify a working directory for the remote Linux nodes, other than the default
temp directory.
Select one of the following Remote Spawn Commands to connect to the remote node:
SSH (the default) will use SSH to spawn nodes from the local Windows machine to the Linux head node as well as from the Linux head node to the compute nodes. To use SSH with Ansys Fluent, you must set up password-less SSH access.
Other allows you to provide other compatible remote shell commands.
Enable the Use Remote Cluster Head Node
field and specify the remote node to which Ansys Fluent will connect for spawning (for example,
via ssh). If this is not provided, then Ansys Fluent will try to use
the first machine in the machine list or file (defined using the Distributed
Memory on a Cluster run type in the Parallel Settings tab).
If SGE, PBS Professional, or Slurm is chosen as the job scheduler, then the same purpose
will be served by Submission Host or (for SGE) SGE
qmaster.
In addition to using the settings in the Remote tab in Fluent Launcher, the following command line options are also available when starting Ansys Fluent from the command line:
-
-nodepath=path is the path on the remote machine where Ansys Fluent is installed.
-
-node0=machine name is the machine from which to launch other nodes.
-
-nodehomedir=directory is the directory that becomes the current working directory for all the nodes. Additionally, this will be used as a scratch area for temporary files that are created on the nodes.
-
-rsh=secure shell command is the command that will be used to launch executables remotely. This option defaults to
ssh.exebut can point to any equivalent program. The form of this command should be that it should not wait for additional inputs such as passwords. For example, if you install SSH, and try to launch in mixed mode usingssh, the launch may fail unless you have set up a login for SSH without a password.
As there are known issues with launching Ansys Fluent in mixed Windows/Linux mode from
cygwin, it is recommended that you use the command prompt
(cmd.exe).
When working with mixed Linux and Windows runs that employ user-defined functions (UDFs), note the following:
The file that you have opened for reading / writing on the host machine will not be available on remote nodes and vice-versa. You may therefore have to transfer data present on the nodes to the host and write it from host, (or distribute the data from the host to the nodes after reading the data from the host).
The loading of multiple UDF libraries into the same session is not supported. As a workaround, you can compile multiple UDF files into same UDF library.
By selecting the Use Remote Linux Nodes option and the Use Job Scheduler option in Fluent Launcher, you can set job scheduler options for the remote Linux machines you are accessing for your CFD analysis.
When these options are enabled in Fluent Launcher, you can use the Scheduler tab to set parameters for either LSF, SGE, PBS Professional, or Slurm job schedulers. You can learn more about each of the schedulers by referring to the Load Management Documentation.
The following list describes the various controls that are available in the Scheduler tab:
- Use LSF
allows you to use the LSF job scheduler.
- Use Checkpointing
allows you to use checkpointing with LSF. By default, the checkpointing directory will be the current working directory. You can set the following:
- Checkpointing Directory
allows you to specify a checkpointing directory that is different from the current working directory.
- Automatic Checkpoint with Setting of Period
allows you to specify that the checkpointing is done automatically at a set time interval. Enter the period (in minutes) in the field, otherwise checkpointing will not occur unless you call the
bchkpntcommand.
- Use SGE
allows you to use the SGE job scheduler.
- SGE qmaster
is the machine in the SGE job submission host list. SGE will allow the SGE qmaster node to summon jobs. By default, localhost is specified for SGE qmaster. Note that the
 button allows you to check the job status.
button allows you to check the job status.- SGE Queue
is the queue where you want to submit your Ansys Fluent jobs. Note that you can use the
 button to contact the SGE qmaster
for a list of queues. Leave this field blank if you want to use the default
queue.
button to contact the SGE qmaster
for a list of queues. Leave this field blank if you want to use the default
queue.- SGE pe
is the parallel environment where you want to submit your Ansys Fluent jobs. The parallel environment must be defined by an administrator. For more information about creating a parallel environment, refer to the SGE documentation. Leave this field blank if you want to use the default parallel environment.
- Use PBSPro
allows you to use the PBS Professional job scheduler.
- Use Slurm
allows you to use the Slurm job scheduler.
- Account
specifies the Slurm account.
- Processes Per Node
specifies the number of node processes per cluster node (rather than leaving it to the cluster configuration).
- GPUs Per Node
specifies the number of GPUs per cluster node. This is only available for editing if you have enabled the Native GPU Solver option in the Home tab.
You have the following options under Options:
- Submission Host
specifies the submission host name for submitting the job. This is needed if the machine you are using to run the launcher cannot submit jobs to the job scheduler. This is only available for LSF, PBS Professional, and Slurm.
- Queue
specifies the queue name or (for Slurm) partition name. This is only available for LSF, PBS Professional, and Slurm.
Important: While running on remote Linux machines using any one of the Job Scheduler options, if the submitted job is in the job queue because of unavailable requested resources, then the Ansys Fluent graphical user interface will remain open until resources are available and the job starts running.
Note: If you experience poor graphics performance when using a job scheduler in Linux, you
may be able to improve performance by specifying that Cortex run on a specified machine
when you start Fluent. This can be done by using the
-scheduler=<scheduler> command line option with
-gui_machine=<hostname> or
-gui_machine (see Scheduler Options and
Graphics and Files Options), or by selecting Specify
Machine or Current Machine from the Graphics
Rendering Machine list in the Scheduler tab of
Fluent Launcher. When running under Slurm, such specification is also needed to allow
dynamic spawning (which is described in Dynamically Spawning Processes Between Fluent Meshing and Fluent Solution
Modes), as
well as the combination of Slurm + Open MPI + distributed memory on a cluster.