


Processing in Ansys Fluent involves an interaction between Ansys Fluent, a
host process, and one or more compute-node processes. Ansys Fluent interacts with the host process
and the compute node(s) using a utility called cortex that manages
Ansys Fluent’s user interface and basic graphical functions.
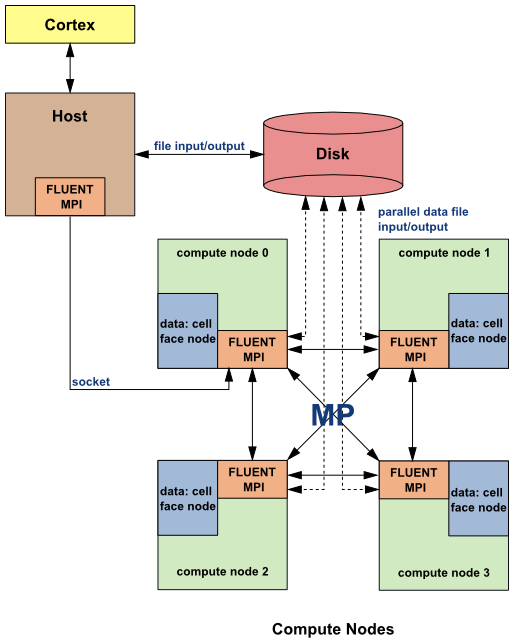
For serial processing, the Ansys Fluent solver uses only a single compute node. For parallel processing, a solution is computed using multiple compute nodes that may be executing on the same computer, or on different computers in a network (Figure 43.1: Ansys Fluent Architecture).
Parallel Ansys Fluent splits up the mesh and data into multiple partitions, then assigns each mesh partition to a different compute node. The number of partitions is equal to or less than the number of processors (or cores) available on your compute cluster. The compute-node processes can be executed on a massively parallel computer, a multiple-CPU workstation, or a network cluster of computers.
Generally, as the number of compute nodes increases, turnaround time for solutions will decrease. This is referred to as solver “scalability.” However, beyond a certain point, the ratio of network communication to computation increases, leading to reduced parallel efficiency, so optimal system sizing is important for simulations.
Ansys Fluent uses a host process that does not store any mesh or solution data. Instead, the
host process only interprets commands from Ansys Fluent’s graphics-related interface,
cortex.
The host distributes those commands to the other compute nodes via
a socket interconnect to a single designated compute node called
compute-node-0. This specialized compute node distributes the host
commands to any additional compute nodes. Each compute node simultaneously executes the same
program on its own data set. Communication from the compute nodes to the host is possible only
through compute-node-0 and only when all compute nodes have
synchronized with each other.
Each compute node is virtually connected to every other compute node, and relies on inter-process communication to perform such functions as sending and receiving arrays, synchronizing, and performing global operations (such as summations over all cells). Inter-process communication is managed by a message-passing library. For example, the message-passing library could be a vendor implementation of the Message Passing Interface (MPI) standard, as depicted in Figure 43.1: Ansys Fluent Architecture.
All of the parallel Ansys Fluent processes (as well as the serial
process) are identified by a unique integer ID. The host collects messages from
compute-node-0 and performs operations (such as printing,
displaying messages, and writing to a file) on all of the data.
For additional information, see the following section:
The recommended procedure for using parallel Ansys Fluent is as follows:
Select your case file by clicking under Get Started With... in the Fluent Launcher.
Specify the number of parallel processors and start Ansys Fluent. For details, see Starting Parallel Ansys Fluent on a Windows System and Starting Parallel Ansys Fluent on a Linux System.
Review the partitions and perform partitioning again, if necessary. See Checking the Partitions for details on checking your partitions. Note that there are other approaches for partitioning, including manual partitioning in either the serial or the parallel solver. For details, see Mesh Partitioning and Load Balancing.
Calculate a solution. See Checking and Improving Parallel Performance for information on checking and improving the parallel performance.
Note: Due to limitations imposed by several MPI implementations, Ansys Fluent performance on heterogeneous clusters involving either operating system or processor family differences may not be optimal, and in certain cases cause failures. You are urged to use caution in such parallel operating environments.