By default, Ansys Fluent writes case and data files in the Common Fluids Format (CFF). CFF files offer greatly improved read and write performance compared to legacy files and can be postprocessed in CFD-Post and EnSight, as well as in third-party products. A case file contains a mesh and settings for your specific problem. Solution data are typically saved in a separate data file related to the case file where the mesh and settings are stored.
The CFF format is based on the HDF5 format, which is an open-source hierarchical data format and a library of APIs that provides a near-random access to any dataset in both serial and parallel processing environments. All settings are saved as formatted strings in multiple groups of CFF files. Heavy-weight data are stored as a 1D or 2D array in the HDF5 dataset. Additional light-weight data (such as minimum and maximum IDs, total number of elements/subgroups, and so on) are added to the groups and dataset as attributes.
Information is presented in the following sections:
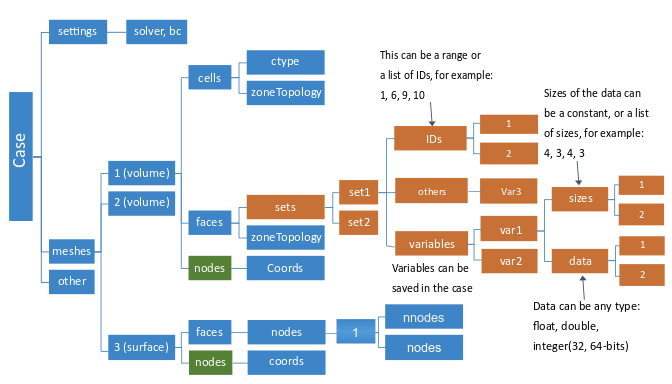
Figure 1: The CFF Case File Layout schematically shows a structure of a CFF case file.
A case file contains the following groups:
meshesThe
meshesgroup stores mesh data and can host multiple meshes. Each mesh is stored in a separate subgroup with an integer ID as the section name. The ID is currently not used, and only one section is expected (ID = 1). The connectivities of faces, cells and nodes are each stored in separate sections calledfaces,cells, andnodes, respectively. The connectivity is local to each mesh. All these settings are saved as formatted strings in multiple file sections. Any lightweight settings are stored within a specific section.settingsThe
settingsgroup stores information about case settings, which include:Physical models
Solver settings
Boundary conditions
Materials
Each solver can write its settings in its native format as strings that can be read back natively.
other(optional)The
othergroup is used by specific solvers to save any mesh-related data other than those stored in themeshesgroup. These data will normally be consumed by the original solver that wrote it. If it is consumed by other parties, a certain agreement will be used between the parties involved.
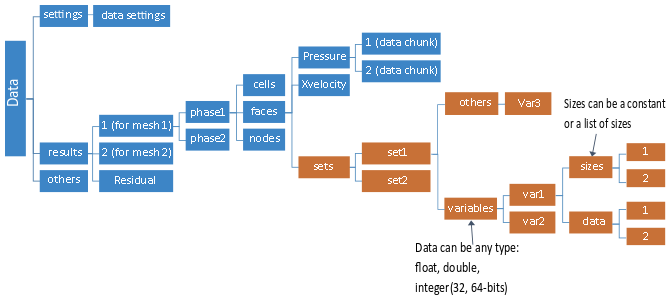
Figure 2: The CFF Data File Layout schematically shows a structure of a CFF data file.
A CFF data file contains the following groups:
resultsThe
resultsgroup stores solution data. This group hosts results for multiple meshes, each related to the same mesh ID used in themeshesgroup in the case file. For a multiphase problem, eachresultsgroup has aphasesubgroup under each mesh (for exampleresults/1/phases-1/) that stores the results for this specific phase. The name of the node (for examplephase-1,phase-2, and so on) is synchronized with the phase ID attribute. Under eachphasesubgroup, one or more zone type sections are defined; each zone type contains a list of relevant variables. Lists of variables for different zone types can be different. A data sectionfieldslists all available variables as a string for each zone type.settingsThe
settingsgroup stores solution-specific settings (such as time step, solver time, and so on). The group contains lightweight data. Each solver writes its settings in its native format as strings that can be read back natively.other(optional)The
othergroup stores any solution data associated with meshes in the corresponding case file. These data will normally be consumed by the original solver (usually by Ansys Fluent).
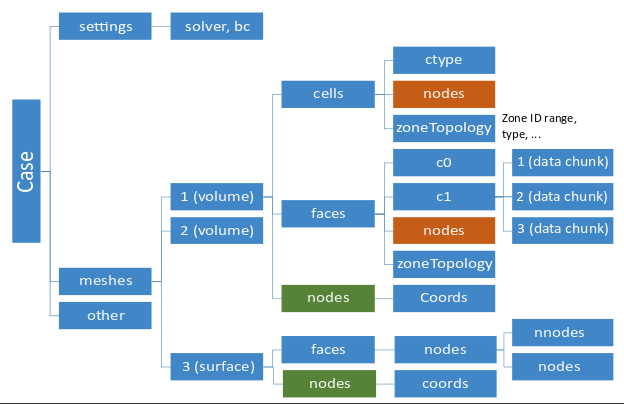
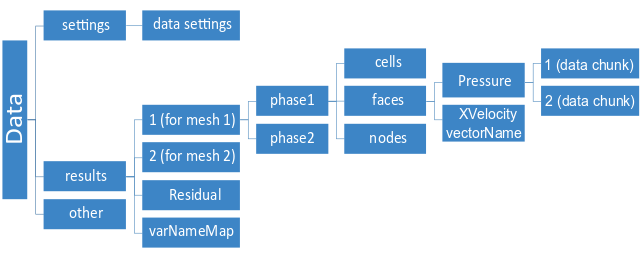
Other special data only store information related to specific models (such as the radiation model). They are organized in sets that hold data on a collection of cells/faces/nodes, where their IDs may not be contiguous. With these sets, any data can be saved as needed. The set data will be appended to the case or data files under corresponding zone group.
The data associated with elements can be of either a constant or variable length. For the variable length data, the sizes and data are saved in two separate 1D arrays (see Figure 3: Variable Sized Data Appended to the Case File and Figure 4: Variable Sized Data Appended to the Data File).