


In order to provide a distributed memory solver for Ansys Polyflow, MUMPS (Multifrontal Massively Parallel Solver) has been added, and in shared memory and in distributed memory.
MUMPS is a package for solving systems of linear equations of the form Ax=b, where A is a square sparse matrix. As the AMF solver used by default in Ansys Polyflow, MUMPS implements a direct method based on a multifrontal approach which performs a Gaussian factorization
 | (31–2) |
where  is a lower triangular matrix and
is a lower triangular matrix and  an upper triangular matrix.
an upper triangular matrix.
Similarly to the AMF solver, the system is solved in three main steps:
Analysis
During the analysis, Mumps creates the elimination tree (variables elimination order) and estimates the number of operations and the memory necessary for the factorization and the solution.
Factorization
The factorization computes the
 and
and  matrices and stores them in double precision. They can be
stored in core memory or on disk.
matrices and stores them in double precision. They can be
stored in core memory or on disk. Solution
The solution is obtained through a forward elimination step:

(31–3)
followed by a backward elimination step

(31–4)
MUMPS in shared memory uses more memory than the AMF solver. AMF stores the
factorized matrix  in single precision, while MUMPS stores it in double precision.
Therefore, MUMPS can use close to two times more memory than AMF and reach the
memory limit of the computer.
in single precision, while MUMPS stores it in double precision.
Therefore, MUMPS can use close to two times more memory than AMF and reach the
memory limit of the computer.
The storage of the factorized matrix on fast disk (SSD) helps reduce the core memory usage, with only a
small impact on CPU.
Moreover, to distribute the memory footprint on several machines, Ansys Polyflow can use the MPI version of the MUMPS linear solver. See Distribute-Memory Parallel (DMP) Analysis for Ansys Polyflow for more details about motivation, run and installation.
You can select the solver through the Numerical parameters menu of the F.E.M. Task.
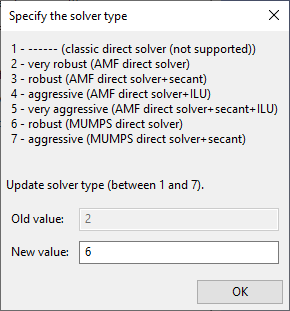
To activate the out of core (OOC) storage of the factor's matrix, that is, storage on disk, add the .p3rc keyword MUMPS_AUTO_SWITCH_OOC_MEMORY NNN, where NNN is a memory size given in MBytes. If the estimated memory evaluated by MUMPS is greater than NNN, then the out of core storage is used by MUMPS.
Note: The MUMPS solver can exploit GPUS. However, the performance gain has been found rather limited for standard problem sizes. Improvements are under investigation. Moreover, the use of GPU by MUMPS on cluster is not available.
In terms of evolution/transient steps and iterations, the AMF and MUMPS solvers behave similarly. Extensive testing on about a thousand cases has revealed that about only 1% exhibited any convergence issues.
In most cases, the MUMPS solver is recommended.
If the CPU time is dominated by the system resolution (large 3D extrusion problems or large 3D problems with contact), MUMPS can reduce the CPU time by about 25 - 30% with peak value up to 50%. The additional memory requirement can reach 200 - 300%. If Out-Of-Core storage is invoked, this additional memory requirement is only 10 to 20% with a CPU penalty of a few percents on fast disks. If the memory requirement is too large, even with the use of the Out-0f-Core Storage, the run with distributed memory on a cluster is possible selecting a number of nodes suitable for the memory available on each node. See DMP Analysis on a Cluster..
If the CPU time is not dominated by the solver (2D problems, problems with contact evaluation, problems with mesh refinement) the benefit of MUMPS in term of CPU is around 10% with peak value up to 20%. Usually, for these kind of problems, the memory is not an issue.