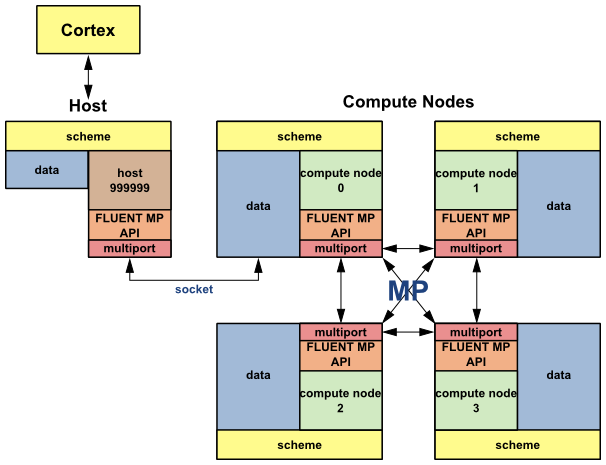
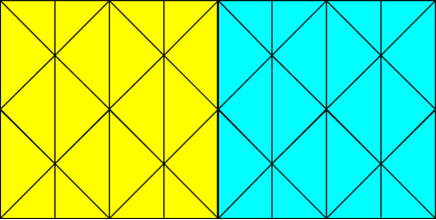
Ansys Fluent’s parallel solver computes a solution to a large problem by simultaneously using multiple processes that may be executed on the same machine, or on different machines in a network. It does this by splitting up the computational domain into multiple partitions (Figure 7.1: Partitioned Mesh in Parallel Ansys Fluent) and assigning each data partition to a different compute process, referred to as a compute node (Figure 7.2: Partitioned Mesh Distributed Between Two Compute Nodes). Each compute node executes the same program on its own data set, simultaneously, with every other compute node. The host process, or simply the host, does not contain mesh cells, faces, or nodes (except when using the DPM shared-memory model). Its primary purpose is to interpret commands from Cortex (the Ansys Fluent process responsible for user-interface and graphics-related functions) and in turn, to pass those commands (and data) to a compute node which distributes it to the other compute nodes.
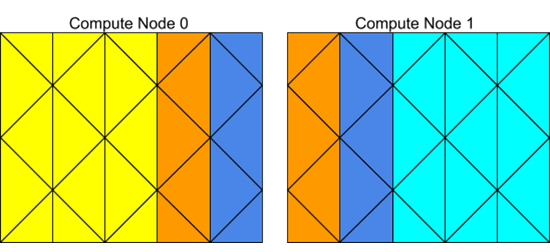
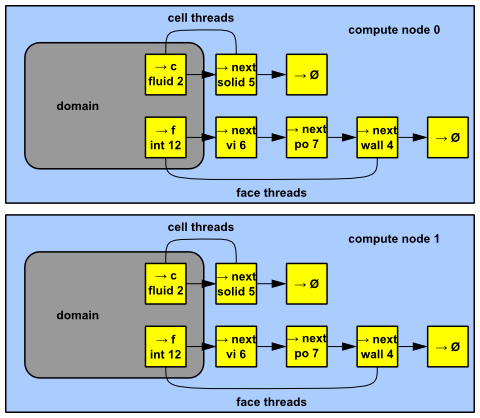
Compute nodes store and perform computations on their portion of the mesh while a single layer of overlapping cells along partition boundaries provides communication and continuity across the partition boundaries (Figure 7.2: Partitioned Mesh Distributed Between Two Compute Nodes). Even though the cells and faces are partitioned, all of the domains and threads in a mesh are mirrored on each compute node (Figure 7.3: Domain and Thread Mirroring in a Distributed Mesh). The threads are stored as linked lists as in the serial solver. The compute nodes can be implemented on a massively parallel computer, a multiple-CPU workstation, or a network of workstations using the same or different operating systems.
For more information, see the following section:
The processes that are involved in an Ansys Fluent session are defined by
Cortex, a host process, and a set of n compute node processes (referred
to as compute nodes), with compute nodes being labeled from 0 to
n-1 (Figure 7.4: Ansys Fluent Architecture). The
host receives commands from Cortex and passes commands to compute node-0. Compute node-0, in
turn, sends commands to all additional compute nodes. All compute nodes (except 0) receive
commands from compute node-0. Before the compute nodes pass messages to the host (via
compute node-0), they synchronize with each other. Figure 7.4: Ansys Fluent Architecture shows the relationship of processes in
Ansys Fluent.
Each compute node is "virtually" connected to every other compute node and relies on its "communicator" to perform such functions as sending and receiving arrays, synchronizing, performing global reductions (such as summations over all cells), and establishing machine connectivity. An Ansys Fluent communicator is a message-passing library. For example, it could be a vendor implementation of the Message Passing Interface (MPI) standard, as depicted in Figure 7.4: Ansys Fluent Architecture.
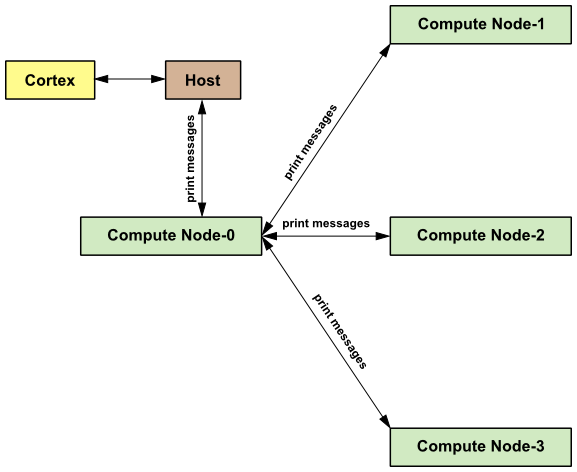
All of the Ansys Fluent processes (including the host process) are
identified by a unique integer ID. The host process is assigned the ID
host(=999999). The host collects messages from compute node-0 and
performs operation (such as printing, displaying messages, and writing to a file) on all of
the data (see Figure 7.5: Example of Command Transfer in Ansys Fluent).