


Normal operation of EnSight involves one client process (the graphics and user interface) interfacing with one server process (data I/O and computation) to postprocess your data. There are however several other configurations possible. One of these is the ability to connect a single client to multiple servers at the same time, with each server maintaining a unique dataset. Each of these servers can potentially run on different machines.
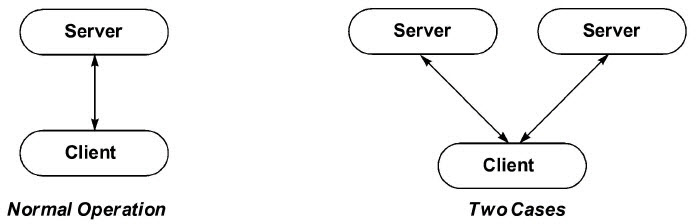
The main use of this capability is to visualize multiple, different datasets simultaneously. Each dataset is loaded into a separate case and can be viewed in the same window or in separate viewports. You can perform before and after comparisons of the same problem or compare experimental with simulated results. The same operation (such as a clip or a particle trace) can be performed in both cases simultaneously. Created parts always belong to the same case as the parent from which the part was created.
As a consequence, you cannot perform operations that combine parts (such as a merge) from multiple cases. If you wish to perform operations with the parts and variables available among the datasets and the datasets are EnSight Case Gold and they are similar (transient or static variables, node and element ids the same, etc) and you want to load all the cases together into one EnSight case, then you can use the Multiple Case File option in the EnSight Data Reader dialog to interactively choose all the datasets that you wish to load together (see Multiple File Interface).
When EnSight reads a new case, it searches the current list of variables for matches with the variables from the new case. If it finds a match (based on an exact match of the variable name), it will not enter the new variable in the list. Rather, the matched name will be used for both. This behavior is based on the assumption that the identical variable names represent the same physical entity and should therefore be treated the same. If the new variable name does not match any existing name, the new variable is added to the list as usual.
Up to 32 cases can be active at one time. You can add a new case or replace an existing case to a running session by using the File → Open... process (if you want to load all parts and don't need to control other options available when loading cases) or the File → Data (reader)... process (which provides greater control). Adding a case starts a new server process, connects it to the client, and either loads all the parts (if you used Open...) or allows you to specify the data format and files as well as which parts to load into the new server and what optional settings to use as the case is created. One of the helpful uses of the replace case option is to load a new dataset into EnSight without re-starting the client. You can of course also delete cases you no longer need.
It is possible to allow EnSight to link cases together in which operations performed on one case are performed on all cases. See the Release Notes for a list of limitations and for details on linking cases see Compare Cases.