


Significant Differences
In Ansys Sound: Jury Listening Test, Significant Differences allow you to assess if the average rating difference between each pair of sounds is meaningful, under a rigorous statistical framework.
In such a case, the two average ratings are said to be significantly different. In the graph below, every sound which is significantly different to the selected sound is emphasized in blue, while the selected sound is emphasized in pale orange.
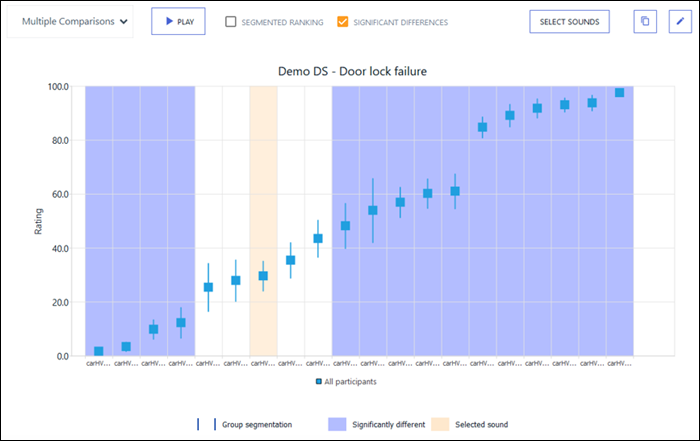
From a statistical standpoint, it is important to look at average ratings in relation to how individual ratings are spread around these average values. If the variability of individual ratings around the average value is low, you can have a stronger confidence in the meaningfulness of that average value than if individual rating variability is high. The same applies to comparing two average ratings: if the average rating difference is large in comparison to the individual variability around each average, you can reasonably conclude that this average rating difference is meaningful, or significant. If, on the other hand, individual variability is much larger than the difference between average ratings, then this difference is most probably not meaningful.
Widely-accepted methods exist to address this question in a very rigorous statistical framework. One of the most common is called the paired Student’s t-test, which provides a way to assess whether or not two average values are significantly different. This also requires selection of a confidence level, the most common choice for which is p<0.05, which means that you can have a 95% confidence in the result of the test.
However, multiplying the application of this test over a large panel of average value pairs, which is termed multiple comparisons, artificially multiplies the chances to wrongfully conclude that some pairs are significantly different (it reduces the confidence level below 95%). In more technical terms, multiple comparisons increase the type I error rate, which is the chance to be wrong when rejecting the null hypothesis (5% here). Fortunately, methods also exist to compensate for that effect.
In Ansys Sound: Jury Listening Test, a Bonferroni-corrected t-test (p<0.05) is used when doing multiple comparisons to determine whether or not two average ratings are significantly different. This test consists of performing paired t-tests between each pair of sound rating distributions. It then compensates for the multiple comparison effect mentioned above by dividing the significance threshold by the number of comparisons done (the number of pairs of sounds). This is called the Bonferroni correction. For example, with 10 sounds and a probability threshold of 0.05, the calculated p-value for each pair of sounds must be below 0.05/45 ≈ 0.001 (10 sounds corresponds to 45 pairs) to conclude that the pair is significantly different.