


Creating an Autoscaling Cluster
Prerequisites: You must be a tenant administrator or have Admin permission in the project space.
Autoscaling cluster workflows are supported for select Ansys applications. These include Ansys Electronics Desktop, Fluids, LS-DYNA, Lumerical, Mechanical, Semiconductor, and Speos applications. Application-specific configurations are available in Recommended Configurations by Application in the Recommended Usage Guide.
Only one autoscaling cluster can be present in a project space at one time. However, the cluster can have multiple job submission queues, and each queue can have a different application associated with it.
To create an autoscaling cluster, follow these steps:
In the project space, select . A Create an Autoscaling Cluster page is displayed.
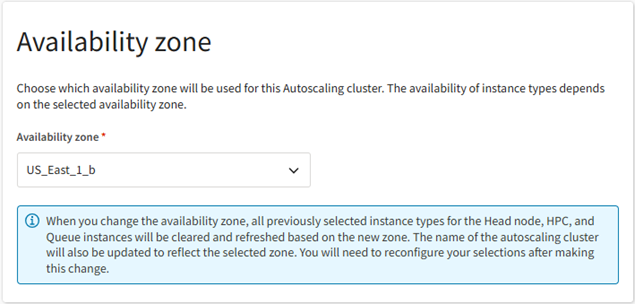
Note: If your company set up Ansys Gateway powered by AWS before March 4, 2025, an alert may be displayed if the tenant administrator has not yet updated the permissions needed to create autoscaling clusters. This task must be completed before autoscaling clusters can be created. See Updating Account Permissions to Allow the Creation of Autoscaling Clusters.In the Availability zone section, select the availability zone where the autoscaling cluster will be created. The selection you make determines which instance types will be available for selection when defining cluster node settings.
In the Licensing section, review or specify the licensing settings for Ansys applications. By default, the licensing settings that are globally configured for your tenant will be used. To view them, expand Global licensing settings.

To override the global licensing settings for this particular resource, enable Use custom licensing settings for this virtual desktop and then configure the settings of the licensing type(s) you want to use.
To use Shared Web Licensing, click Configure next to Shared Web Licensing and then upload a shared web token file.
To use FlexNet licensing, click Configure next to FlexNet licensing.
In the Configure custom FlexNet licensing dialog:
Specify the IP address and optionally the port of a FlexNet server that you want to use. If a port is not specified, 1055 will be used by default.
To add another server to the list, click Add FlexNet license server and specify the server's settings.
When multiple servers are listed, use the arrows in the Priority column to arrange the servers in the order they should be used.
To provide licensing for the LS-DYNA application, specify license server settings in the LSTC license server (optional) area. This is a server where LSTC License Manager is hosted.
Note: Only one LSTC license server can be specified.
- To use Ansys Elastic Licensing, click Configure next to Ansys Elastic Licensing and then specify the Elastic License server ID and Elastic License server PIN.
If you have configured more than one licensing type, use the arrows in the License Priority area to arrange the list in the order in which you would like licensing types to be used. If the first type is not available when licenses are requested, the next type in the list will be used.
Note: Ansys Elastic licensing cannot be moved up in priority. It is always used last.
Note:Once the autoscaling cluster has been created, you cannot change its license settings. To use different license settings, you must create a new cluster.
If you choose to use global license settings, and the global license settings are changed after the cluster is created, the changes will be applied to the cluster when it is restarted.
In the Storage section, specify any existing Amazon storage(s) to be mounted to the cluster or create new storages if desired. A storage is required for application installation. Storages can also be used for simulation files if needed. Simulation files include input and output files and may also include scratch files generated during a solution if local scratch is not used.
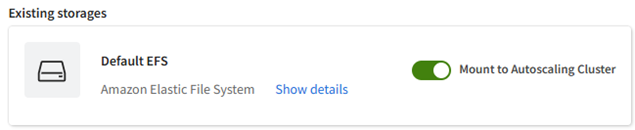
Existing storages
By default, each project space contains an Amazon Elastic File System storage.
Other storages may also be available to be mounted if autoscaling clusters were created in the project space previously. Storages created for previous clusters may already have cluster application packages installed on them, eliminating the need to install those applications on the new cluster.
To mount an existing storage to the cluster, enable the Mount to autoscaling cluster toggle next to the storage in the Existing storages panel.
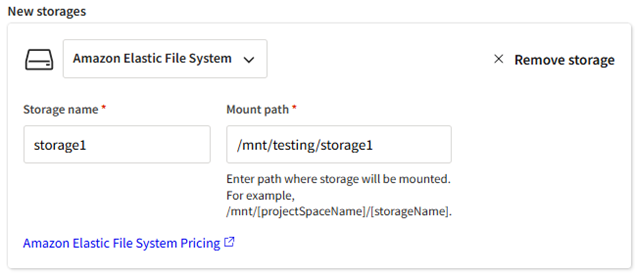
New storages
To create a new storage, click Create storage. A form is displayed.
Define the following.
From the drop-down, select the desired storage type:
Amazon Elastic File System. Recommended for the installation of autoscaling cluster packages. EFS is a simple, scalable file system for general-purpose file sharing and workloads. It offers low latency for frequently accessed files.
This storage type is mounted to Linux virtual desktops in the same project space.
Amazon FSx for Lustre. Recommended for high-performance I/O workflows where speed is a priority. Offers the lowest latency between nodes, millions of IOPS (input/output operations per second), and highest levels of throughput (as much as 1000 gigabytes per second).
This storage type is mounted to Linux virtual desktops in the same project space.
Amazon FSx for OpenZFS. Recommended for high-performance I/O workflows that require advanced data management. Offers the low latency between nodes, 10-21 million IOPS, and high levels of throughput (as much as 10-21 gigabytes per second). The advanced data management capabilities of ZFS maximize storage efficiency when working with massive amounts of data.
This storage type is mounted to both Windows and Linux virtual desktops in the same project space.
For more information, see Types of Shared Storage and Comparison of Amazon Storage Types.
If creating Lustre or OpenZFS storage, specify the storage's configuration settings:
Amazon FSx for Lustre:Setting Description Default value Deployment type Amazon FSx for Lustre provides two file system deployment options: persistent and scratch. Which one you choose depends on how long you need to store data.
Available options are described in Deployment options for FSx for Lustre file systems in the AWS documentation.
Scratch 1 Storage Capacity (GiB) The maximum amount of data that can be stored in the file system. Select the size that will adequately support the size of applications being installed and the anticipated amount of data to be written to the storage when users prepare for and run simulations. 1200 GiB Amazon FSx for OpenZFS:
Setting Description Default value Deployment type Single-AZ options are available: Single AZ 1 and Single AZ 2.
Single AZ options are composed of a single file server instance within one Availability Zone.
Single AZ 2 offers higher levels of performance than Single AZ 1.
For details see Availability and durability for Amazon FSx for OpenZFS in the AWS documentation.
Single AZ 1 Storage Capacity (GiB) The maximum amount of data that can be stored in the file system. Select the size that will adequately support the size of applications being installed and the anticipated amount of data to be written to the storage when users prepare for and run simulations. 64 GiB Throughput How much data can be transferred per second for each tebibyte of storage provisioned 128 MB/s/TiB Specify a Storage name.
- Confirm or specify the Mount path of the storage on the cluster. By default, the mount path is automatically populated with the storage name that you specify in the Storage name field.
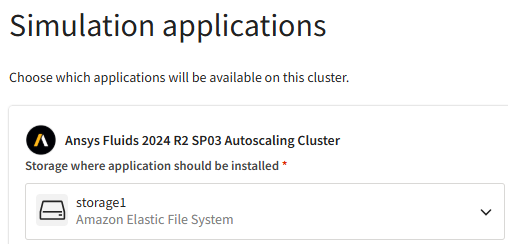
To install one or more applications on the cluster, go to the Simulation applications section and follow the steps below.
Note: If an existing storage containing the desired application(s) is selected to be mounted to the cluster, you can skip this step. The installed application(s) will be detected by the system upon cluster creation. This will speed up cluster creation time as there is no need for application installation.- Click Add an application.
In the Add an application dialog, select the autoscaling cluster application package to install.
Note: You can select more applications to install by clicking Add an application. However, you should be cautious about the number of applications you select as there is a 4-hour time limit on cluster creation. If applications do not get installed within this time frame, cluster creation will fail.Specify the Storage where application should be installed. This dropdown lists the existing and new storages selected for mounting in the Storage section of the wizard.
Optionally, you can create a new storage for application installation by selecting Create new storage in the dropdown.
In the Application configuration area, specify application configuration settings if applicable.
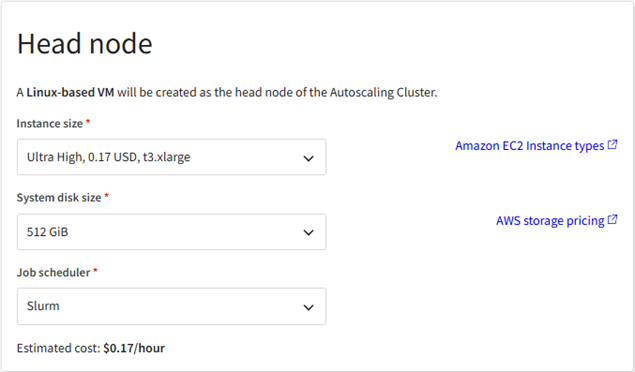
In the Head node section, review the default head node configuration. To change the VM size or system disk size, click Edit head node configuration and make the desired selections for the head node.
For quick application installation, Ansys recommends the 'Ultra High' size.
In the Ansys HPC Platform Services section, specify whether you want to add Ansys HPC Platform Services to this cluster.

Ansys HPC Platform Services is recommended for the following application workflows:
Ansys Electronics Desktop
Ansys Mechanical
Ansys Workbench LS-DYNA
If you are adding Ansys HPC Platform Services to the cluster, specify the following:
Specify where you would like Ansys HPC Platform Services to be installed. Select one of the following:
Create a new VM with Ansys HPC Platform Services. A virtual machine with Ansys HPC Platform Services will be created automatically. This is the recommended option as it allows Ansys HPC Platform Services to run on a machine where it has full use of that machine's resources.
If you select this option, specify the desired instance size and system disk size for the virtual machine to be created.
Install Ansys HPC Platform Services on the same VM as the head node. This option is not recommended because Ansys HPC Platform Services could consume all available system resources on the machine, causing the Slurm controller to hang, or vice versa.
HPS application. The revision of Ansys HPC Platform Services (HPS) to be installed.
Storage where cluster applications are installed. Select the storage that you selected for application installation in the Simulation applications section. Or, if you have chosen to mount an existing storage that already contains the applications to be used with Ansys HPC Platform Services, select that storage.
Provide docker credentials? Specify whether you want to use Docker anonymously or provide Docker credentials (for environments that restrict Docker usage).
Ansys HPC Platform Core Services are delivered via containers. Docker is the engine used to run the containers. When Ansys HPC Platform Services (HPS) is selected for installation on a virtual machine, Docker container images are pulled from Docker Hub.
Note: Ansys recommends that you access Docker Hub using a Docker account instead of anonymously to avoid potential HPS connection issues. For details, see Do I Need a Docker Account to Install HPC Platform Services? in the Recommended Usage Guide.
In the Queues section, define at least one queue for the autoscaling cluster. You can define up to 10 queues.
To define a queue:
Click Add queue.
From the Application dropdown, select the application to run when jobs are submitted to the queue.
Applications such as Ansys Electronics Desktop and Fluids have queue templates available which are tailored specifically for the application being run. To apply a pre-configured template to the queue, select a template from the Queue template dropdown. The queue settings populate automatically with the values defined in the template.
To manually define a queue (if not using a template), follow the remaining steps below.
Specify a Queue name with no spaces. The name must start with a letter and can only contain lowercase letters, numbers, and dashes.
Note: The queue name cannot contain the strings -dy-1 or -st-1.In the Node options specify the number of nodes as described below.
Static nodes per compute resource. Static nodes are virtual machines that are provisioned right away and remain constantly available throughout the life of the cluster. Static nodes are not a requirement for autoscaling clusters. A value of 0 is acceptable. A non-zero value should only be specified when you need persistent, reliable access to a certain number of virtual machines.
Maximum dynamic nodes per compute resource. Dynamic nodes are virtual machines that are provisioned as needed to meet workload demands. Dynamic nodes are what support autoscaling functionality. Specify the maximum number of dynamic nodes that can be provisioned for each compute resource.
Note: When you define a compute resource for the queue, a Maximum number of nodes value is displayed in the Node options area. This value lets you know the maximum number of nodes (static + dynamic) that can be specified based on the quota available for the selected instance size(s).If the number of nodes specified exceeds the available quota, an error message is displayed:

In the Advanced node options you can specify the following:
Enable Elastic Fabric Adapter. When running applications in a highly iterative fashion (CFD, for example), data must be distributed globally over the cluster for frequent recalculation. Elastic Fabric Adapter (EFA) is a network interface that enhances performance of inter-node communication for lower latency and higher throughput.
Note: Toggling this option changes the instance types that are available for selection. Only some instance types support EFA.Disable simultaneous multithreading. Simultaneous multithreading is a technology that allows a single physical processor core to behave like two logical processors, essentially allowing two independent threads to run in parallel. This enables more data to be processed in less time, improving performance and efficiency. By default, simultaneous multithreading is disabled.
Create all nodes in the same Placement Group. A placement group ensures that compute resources are physically located close to each other. Deploying virtual machines within a placement group ensures the lowest possible latency between cluster nodes.
System disk size. The capacity of the operating system disk.
Note:- When Create all nodes in the same Placement Group is enabled, a queue can have a maximum of 100 nodes.
- If Elastic Fabric Adapter is enabled, a placement group will be used even if you disable the Create all nodes in the same Placement Group setting in the queue definition. The 100-node maximum still applies in this case.
In the Compute resources section, click Add resource. A compute resource is a selection of one or more instance sizes that can be used for the creation of nodes in this queue.
To define a compute resource, click Add instance size and select an instance size that you would like to use. As soon as you make a selection, the list is automatically filtered to display other instance sizes with the same number of physical cores and GPUs, and the same GPU manufacturer. If you select more than one instance size for a compute resource, these specifications (cores/GPUs/GPU manufacturer) must be the same across instance sizes. The cluster prioritizes using the most cost-effective resources first.
For a quick reference on suitable hardware for each application, see Recommended Instance Types for Cluster Workflows in the Recommended Usage Guide.
To add more instance sizes to the compute resource definition, click
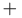 next to the compute resource drop-down.
next to the compute resource drop-down.
If desired, you can create additional compute resources with one or more instance sizes per resource. To create another compute resource, click Add resource and select the desired instance size(s).
In the Additional cluster options section, select a time for dynamic nodes to be terminated after node shutdown. The default is 10 minutes.
As submitted jobs finish, the nodes that were dynamically provisioned to do the work are shut down but remain available for a specified period of time before being deallocated. This setting determines the period of time before deallocation.
In the Autoscaling Cluster name field, specify a name for the autoscaling cluster as you would like it to appear in the resource list in the project space.
In the Cost summary section, review the estimated cost of running the cluster. If desired you can go back and change the head node and queue configurations.
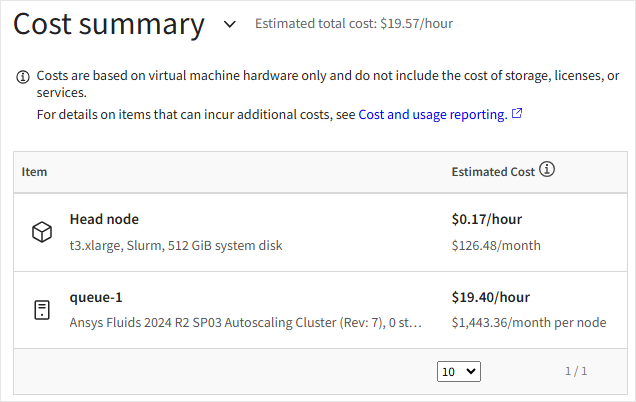
When all settings have been defined, click Create autoscaling cluster. The cluster is started.
 Note:
Note:If any fields are incomplete, an error message is displayed. Go back through the form and fill out any missing information. At least one simulation application must be installed. Also, make sure that you have fully defined the head node and created at least one queue. Each queue must have an application and compute resource defined.
Cluster creation can take more than 30 minutes depending on the number of applications being installed.
Restarting a stopped cluster can also take more than 30 minutes.
When the cluster is in the Running state, users can use a virtual desktop in the same project space to copy input files to the shared storage and submit jobs to it from a virtual desktop in the same project space. See Submitting a Job to an Autoscaling Cluster in the User's Guide.
The Slurm client application is automatically installed on Linux virtual desktops. When you create an autoscaling cluster in a project space that contains a Linux virtual desktop, a connection between the autoscaling cluster and virtual desktop is automatically established, enabling you to submit jobs to the cluster from the virtual desktop. If for some reason the connection becomes broken, you can reestablish it by following the instructions in Restoring a Connection to a Slurm Autoscaling Cluster in the Troubleshooting Guide.
Once an autoscaling cluster has been created, you should only interact with it via Ansys Gateway powered by AWS, not AWS portal.