


EnSight, using an Enterprise license key has the capability of handling partitioned data in an efficient distributed manner by utilizing what we call a server-of-servers (SOS for short). An SOS server resides between a normal client and a number of normal servers. Therefore, it appears as a normal server to the client, and as a normal client to the various normal servers.
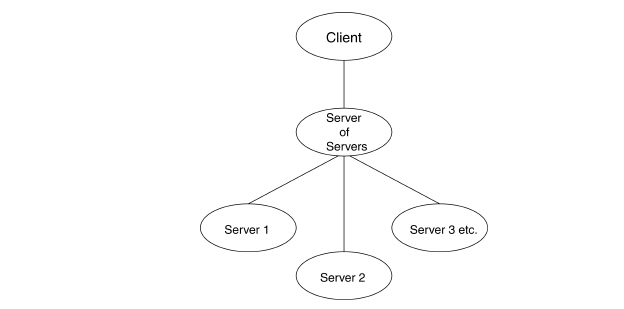
This arrangement allows for distributed parallel processing of the various portions of a model, and has been shown to scale quite well.
Currently, EnSight SOS capability is only available for EnSight5, EnSight6, EnSight Gold, Plot3d, and any EnSight User-Defined Reader data.
Please recognize that your data must be partitioned in some manner (hopefully in a way that will be reasonably load balanced) in order for this approach to be useful. The exception to this is the use of the auto_distribute capability for structured or unstructured data. This option can be used if the data are readable by all servers. It will automatically distribute each portion of the data over the defined servers - without the user having to partition the data. Please note that currently only EnSight Gold, Plot3d, and any 2.06 (or greater) user-defined readers (which have implemented structured reader cinching) should be used for structured auto_distribute - and that only EnSight Gold and any 2.08 (or greater) user-defined readers (which have implemented the "*_in_buffers" routines ) should be used for unstructured auto_distribute. Using an EnSight reader not written for SoS autodistribute will result in each server loading the entire model.
Included in the EnSight distribution is a command-line utility named partition that will take most EnSight Case Gold binary unstructured datasets and spatially decompose the geometry into separate datasets by partitioning the geometry. Simply type partition at the command prompt to begin. This command line program will prompt you for the name of the input case file and the number of partitions in the x, y, and z and whether or not to use ghost elements, etc. and will create (in a directory of your choosing) a case sos file (.sos) pointing to the spatially-decomposed, partitioned case files ready for loading into EnSight server of server mode.
If the partitioned EnSight Case Gold files all remain on a network file system accessible by all the EnSight servers, then you can bypass the SOS casefile and simply use multi-case, see Read Data and Multiple File Interface.
Note: If you do your own partitioning of data into EnSight6 or EnSight Gold format, please be aware that each part must be in each partition - but, any given part can be "empty" in any given partition. All that is required for an empty part is the "part" line, the part number, and the "description" line. If you use ENSHELL to start up your servers, and your format is EnSight Gold, then your SOS case file can be greatly simplified to just list the case files (see Load Spatially Decomposed Case Files ).
Each spatially decomposed partition dataset is actually a self contained set of EnSight data files, which could be successfully read by a normal client - server session of EnSight. For example, for EnSight gold format, there will be a casefile and associated gold geometry and variable results file(s). For optimal performance you can place each spatially decomposed Case Gold dataset of the model on the local file system of computer that will access that portion. You cannot use the Multiple File Interface if you manually place the spatially decomposed datasets on different computers. Rather you must use a SOS Casefile that is a simple, ASCII file which informs the SOS about pertinent information need to run a server on each computer that will host the EnSight server (and SOS) process(es) and what path and file(s) it needs to read.
Note: You will need to place the SOS casefile on the machine where the EnSight SOS will be run.
The format for the SOS casefile is as follows:
Note: [ ] indicates optional information, and a blank line or a line with # in the first column are comments.
Table 10.1: Format
| FORMAT | Required |
| type | master_server datatype (Required) |
| where | datatype is required and is one of the formats of EnSight's |
| internal readers (which use the Part builder) |
Note: For user-defined readers, the string
must be exactly that which is defined in the
|
If datatype is blank, it will default to EnSight6 data type.
| [auto_distribute: server/reader/on/off] | Optional for structured or unstructured data Set this option to off if you have moved the decomposed data file(s) into separate directories or machines. Each server will simply read all of the data as specified in its data_path and casefile below. Set this option to
on or server
(these two options are the same) if you want the EnSight server
to automatically distribute data to the servers specified below.
This requires that each of the servers have access to the same
data (or identical copies of it). For structured data: use the
ON or Server
option only if the datatype is gold, plot3d or a 2.06 or greater
user-defined reader (which has implemented structured cinching).
For unstructured data: use only if the datatype is gold, or a
2.* user-defined reader (which has implemented the
Set this option to
reader if you want EnSight to allow
the readers to do the decomposition. This option requires that
each of the servers have access to the same data (or identical
copies of it). This is preferred over letting the server do the
distribution. However the reader option
will only work if the reader has told EnSight that it can do
the distribution by setting the return value to TRUE in the
|
| Optional, to use the specification of server machines from EnSight resources; this will override the machine names used in this file, see How To Use Resource Management.) | |
|
[do_ghosts: on/off] | Optional for unstructured auto_distribute - default is off
starting with version 10.1.4(a). Allows user to control whether ghost cells will be produced between the distributed portions. This
action can alternatively be set on by use of the
|
|
[buffer_size: n] | Optional for unstructured auto_distribute and do_ghosts - default
is 100000 Allows user to modify the default buffer size that is used when reading node and element information of the model when producing ghost cells. |
|
[want_metric: on/off] | Optional for unstructured auto_distribute and do_ghosts - default
is off starting with version 10.1.4(a) If set on, a simple metric will be printed in the shell window that can indicate the quality of the auto_distribution. The unstructured auto_distribute method relies on some coherence in the element connectivity - namely, that elements that lie next to each other are generally listed close to each other in the data format. The metric is simply the (#total_nodes / #nodes_needed_if_no_ghosts). When no ghosts, the value will be 1.0. The more ghosts you must have, the higher this metric will be. If the number gets much more than 2.0, you may want to consider partitioning yourself. This
action can alternatively be set on by use of the
|
Note: This whole section is below optional. It is needed only when more than one network interface to the sos host is available and it is desired to use them. Thus distributing the servers to sos communication over more than one network interface.
Table 10.2: Network Interfaces
number of network interfaces:
num | Required - if section used where:
|
network interface:
sos_network_interface_name1 | Required - if section is used |
network interface:
sos_network_interface_name2 | Required - if section is used |
network interface:
sos_network_interface_namenum | Required - if section used |
Table 10.3: Servers
| SERVERS | Required |
number of servers: num | Required where:
|
| #Server 1 | Comment only |
machine id: mid | Required where:
|
| executable: /.../ensight_server | Required, must use full path |
| [directory: wd] | Optional where:
|
| [login id: id] | Optional where:
|
| [data_path: /.../dd] | Optional where:
|
| casefile: yourfile.case | Required, but depending on format, may vary as to whether it is a casefile, geometry file, neutral file, universal file, etc. Relates to the first data field of the Data Reader Dialog. |
| [resfile: yourfile.res] | Depends on format as to whether required or not. Relates to the second data field of the Data Reader Dialog. |
| [measfile: yourfile.mea] | Depends on format as to whether required or not. Relates to the third data field of the Data Reader Dialog. |
| [bndfile: yourfile.bnd] | Depends on format as to whether required or not. Relates to the fourth data field of the Data Reader Dialog. |
| #Server 2 | Comment only |
Note: Repeat pertinent lines for as many servers as declared to be in this file
Example
This example deals with a EnSight Gold dataset that has been partitioned into 3 portions, each running on a different machine. The machines are named joe, sally, and bill. The executables for all machines are located in similar locations, but the data is not.
Note: The optional data_path line is used on two of the servers, but not the third.
FORMAT
type: master_server gold
SERVERS
number of servers: 3
#Server 1
machine id: joe
executable: /usr/local/bin/ensight102/bin/ensight102.server
data_path: /usr/people/john/data
casefile: portion_1.case
#Server 2
machine id: sally
executable: /usr/local/bin/ensight102/bin/ensight102.server
data_path: /scratch/sally/john/data
casefile: portion_2.case
#Server 3
machine id: bill
executable: /usr/local/bin/ensight102/bin/ensight102.server
casefile: /scratch/temp/john/portion_3.case
If we name this example sos casefile "all.sos", and we run it on yet another machine, one named george, the data would be distributed as follows:
On george: all.sos
On joe (in /usr/people/john/data): portion_1.case, and all files referenced by it.
On sally (in /scratch/sally/john/data): portion_2.case, and all files referenced by it.
On bill (in /scratch/temp/john): portion_3.case, and all file referenced by it.
By starting EnSight with the -sos command line
option (which will autoconnect using ensight.sos instead of
ensight_server), or by manually running ensight.sos in
place of ensight_server, and providing all.sos as the
casefile to read in the Data Reader dialog - EnSight will
start three servers and compute the respective portions on them in parallel (see
Command Line Start-up
Options ).
For examples of structured and unstructured auto_distribute, see Use Server of Servers.
If you choose to read spatially decomposed case files using the same number of servers as case files, then this section is unnecessary. At some point you may encounter case files that are spatially decomposed and wish to read them with less servers than you have case files. At that point you will need to have this section with a keyword MULTIPLE_CASEFILES. There are several ways to specify the case files.
List them all by name:
| MULTIPLE_CASEFILES | ||
| total number of cfiles | n | |
| cfiles global path | global_path | Optional |
| cfiles | partition_1.case | |
| partition_2.case | ||
| . | ||
| partition_n.case | ||
| MULTIPLE_CASEFILES | ||
| total number of cfiles | n | |
| cfiles global path | global_path | Optional |
| cfiles pattern | partition_*.case | |
| cfiles start number | # | |
| cfiles increment | # | |
| Use a separate file to containing the case filenames | ||
| MULTIPLE_CASEFILES | |
| total number of cfiles | n |
| cfiles file | all_together_cfilenames.txt |
| cfiles pattern | partition_*.case |
| cfiles start number | # |
| cfiles increment | # |
See Load Spatially Decomposed Case Files for detailed usage instructions.
By default, both the EnSight client and the server start up with an optimum number of threads (depending on the number of processors available and within the EnSight user license limits). Each executable of EnSight can be configured individually to limit the number of threads used. The following environment variables are used to specify the maximum number of threads that the executable should use for computation. These environment variables should be set in your shell startup script on the computers where the various EnSight executables run.
ENSIGHT10_MAX_THREADS
The maximum number of threads to use for each EnSight server. Server threads are used to accelerate the computation of streamlines, clips, isosurfaces, shock surfaces, most calculator functions (see Threaded Calculator Functions) and other compute-intensive operations.
ENSIGHT10_MAX_CTHREADS
The maximum number of threads to use for each EnSight client. Client threaded operations include transparency resort and display list creation.
ENSIGHT10_MAX_SOSTHREADS
The maximum number of threads to use on the server of server (SOS). The SOS uses threads in order to start up server processes in parallel rather than serially.
The number of threads is limited to 8 (per client or server) with a Standard license, while the upper limit for an Enterprise (formerly gold or hpc) license is 128. When setting these parameters it is a good idea to take into account the number of processors on the system. In general, you will not see benefit from setting the parameters higher than the number of total processors. Because the server, server-of-servers and client operate in a pipelined fashion, it is not necessary to limit one in order to apply more threads to another.
If the machine named george had more than one network interface (say it had its main one named george, but also had one named george2), we could add the section shown below to our casefile example:
number of network interfaces: 2
network interface: george
network interface: george2
This would cause machine joe to connect back to george, machine sally to connect back to george2, and machine bill to connect back to george. This is because the sos is cycling through its available interfaces as it connects the servers. Remember that this is an optional section, and most users will probably not use it. Also, the contents of this section will be ignored if the -soshostname command line option is used (see Command Line Start-up Options ).