This page references frequently asked questions regarding the Ansys SimAI platform models.
Training data and Model Performance
Are the Ansys SimAI platform models translation invariant?
Models
remain largely unaffected by data translation during both training and prediction phases.
Adjusting the absolute position of your geometry will not improve your model performance.
However, it can introduce border effects if the geometry is too close to the limits of the
Domain of Analysis. In general, when there is some variance in the absolute position of
your data, use the relative definition of the Domain of Analysis to ensure a proper model
training.
Are the Ansys SimAI platform models rotation invariant?
Models are
sensitive to data rotation. Importing the same geometry with different orientations will
produce different results and, especially, make your model more effective at generalizing
if rotation is an important aspect to study.
Is it possible to anticipate the model's performance during its
construction?
It is impossible to interpret or monitor a model’s performance
during its construction. The most effective approach to achieving satisfactory performance
is to build the model progressively. Begin with a small dataset and a short build
duration. As you gain confidence in your AI model, gradually increase the number of
training data points and extend the build duration, ideally modifying only a few
parameters at a time.
How does the Ansys SimAI platform manage to build models with so little
training data? (when compared with recommended minimum number of data points for other
Neural Network approaches)
By its 3D Deep Learning approach, the model is able
to extract more information from the 3D solution than what another model can extract from
scalar inputs/outputs. There is more information in a 3D field than in a scalar. With that
said, the Ansys SimAI platform still requires some data, just as any Deep
Learning method, and substantially more data when training on scalar
predictions.
For example, consider two use cases that may require more data:
In very specific contexts like statistical or risk assessment approaches, typically
kurtosis prediction, there is no interest in learning the full 3D field as only a
few nodes of the full field are important. Thus, the 3D problem is naturally shrinking
into a "scalar" problem for input. And as a consequence, for this kind of problem, the
Ansys SimAI platform requires more data, as only few important information can
be derived from the 3D field.
When creating a constant field for scalar prediction: since a constant field does not
contain a lot of information to generalize on, the requirement in data increases.
Moreover, the SimAI model is based on continuity.
It uses a continuous function to represent a smooth and predictable relationship
between inputs and outputs over a specified domain.
The function is then sampled
across the domain to discretize the data using collocation points, enabling for
visualization and computation.
Postprocessing functions then use these sampled data
and collocation points to generate outputs/values that can be visualized
(surface.vtp) or integrated across surfaces or volumes to derive
summary metrics (Global Coefficients). These postprocessing functions allow detailed
insights into the model's predictions to assess and validate its performance.
What resolution (number of points/cells) is used to predict the standard volume VTU
files?
The Ansys SimAI platform prediction is a continuous function.
Thus, the output is equivalent to an infinite resolution. You just ask the model to give
you information on a collocation point. As no 3D mesh is submitted when asking for a
standard Volume VTU postprocessing, the Domain of Analysis is used to create a cartesian
mesh with ~2m nodes.
Speed vs Performance
How does prediction time correlate with the number of cells in my
geometry?
The prediction time is approximately linearly correlated with the number
of cells.
Why is there sometimes marginal improvement despite me choosing a longer build
duration?
The learning (training) process of a neural network is an iterative
process in which the calculations are carried out forwards and backwards through each
layer in the network until the model is converged.
When you choose a longer build
duration, you allow the model to train for a higher number of epochs/iterations, but there
is no significant improvement if you are already in the asymptotic state. This mechanism
is similar to how solvers do not improve convergence when they reach a given number of
iterations.
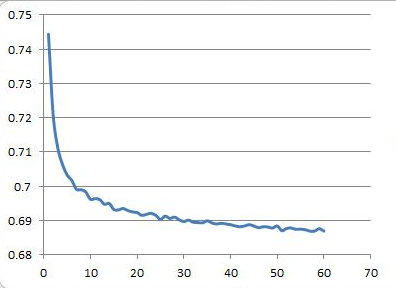
Once you launched a build, the training process cannot be stopped (when
convergence is reached) and it is not possible to detect any asymptotic state during the
process.Figure 1. Example of the convergence of a loss function (y-axis) over iterations
(x-axis)
Can training stage be expedited? Is there any option to leverage from more GPU/CPU for
training?
There is no option to speed up a training by leveraging more GPU/CPU.
In specific conditions, it is possible to build a new AI model on top of the last model
built, speeding up the training process by a factor of 5. For more information about the
Build on top mode, see Building on Top of Previous Model (Deprecated).