
Large Scale DSO Theory
The parametric analysis command in Ansys Electronics Desktop computes simulation results as a function of model parameters, such as geometry dimensions, material properties and excitations. The parametric analysis is either performed on a local machine, where each variation is analyzed serially by a single engine, or distributed across machines through a DSO license. Desktop's DSO analysis runs multiple engines in parallel, thus generating results in a shorter time. In the regular DSO algorithm, the parametric analysis job (Desktop) runs on the primary node, which in turn launches one or more distributed-parallel engines on each machine allocated to the job. Desktop distributes parametric variations among these engines running in parallel. As variations are solved, the progress/messages and variation results are sent back to Desktop, where they are added into the common results database on primary node, as illustrated below:
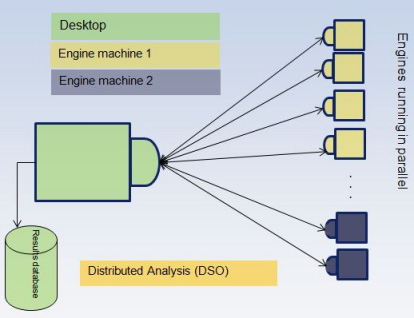
Regular DSO Bottleneck
As illustrated above, regular DSO's speedup is limited by the resources of the centralized “Desktop” bottleneck. It's been observed that DSO becomes unreliable at a certain point, as the number of engines and number of variations increases. The term “large scale parallel” can be used to define this tipping point. For a given model, a “large-scale parallel” job denotes scenarios, in terms of the number of distributed-parallel engines and the number of parametric variations, where the regular DSO runs into centralized bottlenecks that result in progressively smaller speedups and/or unreliability.
With the advent of economical availability and timely provisioning of compute resources, product designers have access to large compute clusters to run their simulations. They are using more compute resources at simulation jobs to obtain results faster. The parametric DSO needs to meet this challenge and target linear speedup for “large-scale parallel” jobs. The large scale DSO feature is targeted toward 100% reliability and linear speedup of large-scale parallel DSO jobs.
Key Algorithms/Concepts for Large Scale DSO
- Embarrassingly Parallel algorithm – Large scale DSO exploits the embarrassingly parallel nature of parametric runs. The solve of each variation is made fully independent of another variation by replacing regular DSO's centralized database with per-engine distributed databases.
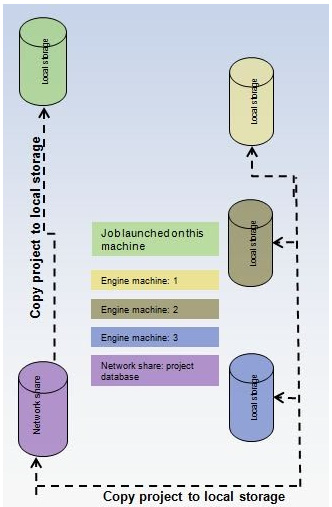
- Distributed databases – For each distributed-parallel engine, the database of the input model
is cloned to local storage of the engine's compute node (as illustrated
in the following picture). Parallel analysis is performed on these cloned
models and the analysis results also go to the corresponding location in
local storage. As each engine has its own database, there is no “shared
database” contention between any two engines. There is negligible network
traffic as analysis/computations are contained in a single machine and
use just the “local resources.”
- Hierarchical activation of engines – In the large scale DSO algorithm, engine activation is done hierarchically, where the overhead of launching of engines is also shared across the nodes. Such hierarchical activation improves reliability of the activation phase of large-scale parallel jobs. A new desktopjob program encapsulates hierarchical activation, as illustrated in the pictures below. In this approach, the “root” desktopjob (Root DJ) activates a “level-one” child desktopjob (DJ(L1)) for each unique node allocated to the DSO job. Each level-one desktopjob activates one or more “leaf” desktopjobs (DJ(L2)) equal to the number of distributed engines per node. A leaf desktopjob in turn runs Desktop in batch mode, to perform local-machine parametric analysis to solve the variations assigned to this engine.
- Decentralized Load balancing – A parametric table is divided into regions of equal number of variations, with the number of regions equal to the number of engines. In the illustration below, the analysis of 30 parametric variations is distributed among five engines. Each engine solves its assigned region as a “local machine” parametric analysis. The large scale DSO job is finished when all engines are done with their assigned variations.
Distributed results postprocessing – As an engine is done with the solve of a variation, it extracts results for the solved variation before progressing to the analysis of next variation. The extracted results are saved to the local storage. When the engine is done with analysis of all variations, the extracted results are transferred from local storage to the results folder of the input project.