Multithreading Technical Notes
Multithreading can save significant time in the causality check calculation, especially for data sets with large number of ports or a large number of frequencies. The Network Data Explorer contributes a fixed amount of overhead time in preparing the data, and this overhead is not reduced by multithreading. Here are the messages from the causality check of a 278-port Touchstone file using two cores.
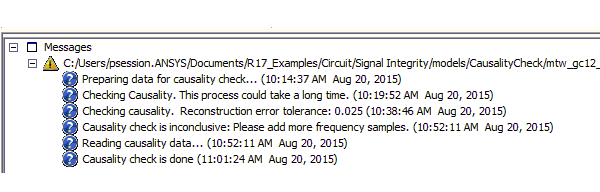
The causality check itself happens between the message Checking causality. Reconstruction error tolerance: 0.025 (time 10:38:46) and the message Causality check is inconclusive: Please add more frequency samples (time 10:52:11). The difference between these two times is the time for the causality check after setup, 13:25 or thirteen minutes and twenty-five seconds. There is a fixed overhead of around 25 minutes involved in the overall time duration for this example.
Here are the causality check messages for the same 278-port file using 8 cores:

Now the causality check happens between times (1:03:55) and (1:10:35), a difference of (6:40) or six minutes and forty seconds, about half the time for the two-core example.
The speedup from multithreading is not linear in practice. Here are the messages from the same 278-port file using 16 cores:
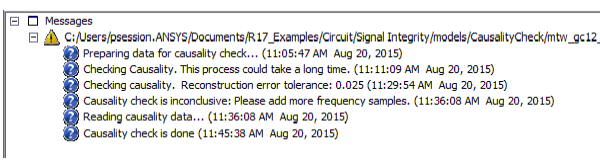
Now the causality check happens between times (11:29:54) and (11:36:08), a difference of (6:14) or six minutes and fourteen seconds, not significantly better than the eight-core performance.
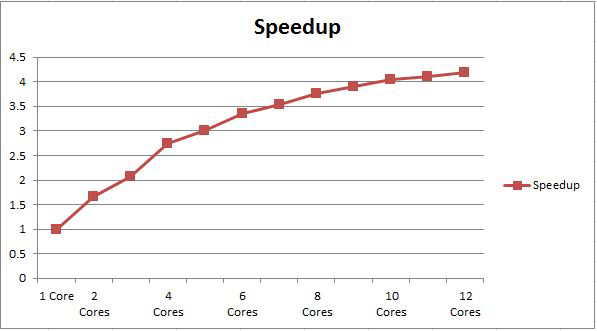
Here is a graph showing the speedup of the causality checker using multithreading on this 278-port file. The plot is generated using data from runs with 1, 2, 4, 6, 8, 10, and 12 cores, then averaging the known times to approximate the speedup for 3, 5, 7, 9, and 11 cores. The speedup for N cores is the time with one core divided by the time with N cores.