
Large Scale DSO Known Issues/Troubleshooting
Node Order
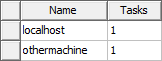
For Large Scale DSO jobs that are submitted from job submission panel using RSM, localhost must be the first node in the resource selection node list, otherwise Large Scale DSO solve with RSM will fail. Set the order in the Submit Job To window, Compute Resources tab:
Cluster Configuration Shared Drive Requirement
All input files (project, etc.) must be present on a shared drive that is accessible from every node of the cluster.
Parallel Task Limitation for LS-DSO Parametric Variations
There some limitations of running short parametric runs in parallel and using a subset of cores and/or running across multiple machines instead of just one. LS-DSO does help in getting close to linear scalability for parametric runs in many scenarios, it has some overheads and typically they are small in comparison to total time of run. However, a few factors in particular scenarios can make them prominent.
The startup of each task involves copying the project and launching ansysedt to solve a subset of parametric table. Typically, one task solves several variations and this startup cost is negligible in comparison to total time. Consider a case where each task is solving only single variation. Additionally the actual solve time of one variation is relatively small, 3-5 minutes. These factors make the startup cost significant. There is also some variance in solve times of different variations. When all variations are solved in parallel, the total time is determined by slowest variation, even though the expectation intuitively might be relative to average time. That could make the perception of overhead worse in this case.
Another important factor is the number of parallel tasks on each machine relative to the total number of cores on the machine. Each task is effectively running an ansysedt of its own and solving subset of parametric table on a copy of project. The solve process does involve significant disk IO. If you run too many tasks on a single machine, they may end up competing with each other for single disk, and that could cause them to slowdown. The conflict in memory access may also become a factor.
In a particular case, 26 tasks were run on one 26 core machine, and this caused significant slowdowns. Spreading the tasks across machines helped scalability as an example with a 32 core machines in a Linux Cloud, we ran this job with 26 tasks on a single machine and then another one over two machines with 13 tasks per machine. The single machine job finishes in about 14 mins, while the job on two machine finishes in about 8.5 mins. This indicates that spreading tasks across machines helps with scalability by minimize file read/write conflicts.
Job Restart
There is no provision for stopping and restarting a job. A new job does not reuse solved results; it always solves all rows in the table. An abort or failure of a job restarts from the beginning, unless a new parametric table with the unsolved rows is created.
Linux-Only Issues
- Deployment/Installation errors (such as mainsoft-related) are not captured. If there is such an issue, the Large Scale DSO job will fail without useful messages in the logs.
- Report-based extraction fails if traces and parametric-setup are not prepared as per the Getting Started guides.
-
Job status: The exit code of job doesn't indicate success or failure correctly. The error messages from multiple log files needs to be combined to determine the reason for failure. In many situations, the reason for a failure is apparent only after re-running the job after turning ON the 'debug logging'.
-
In some LINUX scenarios, the analysis appears to finish successfully with valid results, except that the exit code is '134'. In this case, although the exit is abnormal, the failed exit code can be ignored.
-
Load Balancing: For models with 'unbalanced variations table' (variations that take considerably different amount of time to solve are clustered in few regions of table), job will take longer time to solve than a Regular DSO as the job's overall completion time is determined by the slowest solving region. Workaround: rearrange the rows in the parametric table so that each region takes a similar time to solve.
-
GM Specifics: the model used for 'Report-based extractor' jobs is NOT compatible with the 'Ansys-extractor-for-GM' jobs. A valid model for Ansys-extractor-for-GM cannot contain any of: reports, overlay plots, Optimetrics calculations.