


Elasticsearch deployment options
You should configure an Elasticsearch cluster with enough nodes and the correct configuration to ensure resilience, performance, and scalability of search and indexing features in your Granta MI cluster.
Ansys does not prescribe how you should set up your Elasticsearch environment. Elastic offers several different deployment options to suit your workloads, policies, and deployment needs. The following topics in this document show how to set up a self-managed deployment of Elasticsearch for a Granta MI cluster, but you should choose the approach that best fits your requirements.
Review the information provided in Deploy and manage | Elastic documentation to understand the different deployment options.
Elasticsearch cluster setup
Review the guidance on running Elasticsearch in Production guidance | Elastic documentation, in particular the information on designing a resilient Elasticsearch cluster.
Unless your organization has specific requirements to the contrary, Ansys recommends setting up a resilient homogenous cluster with three nodes, with each node being a master-eligible, generic data node. For HA, at least three master-eligible nodes are required.
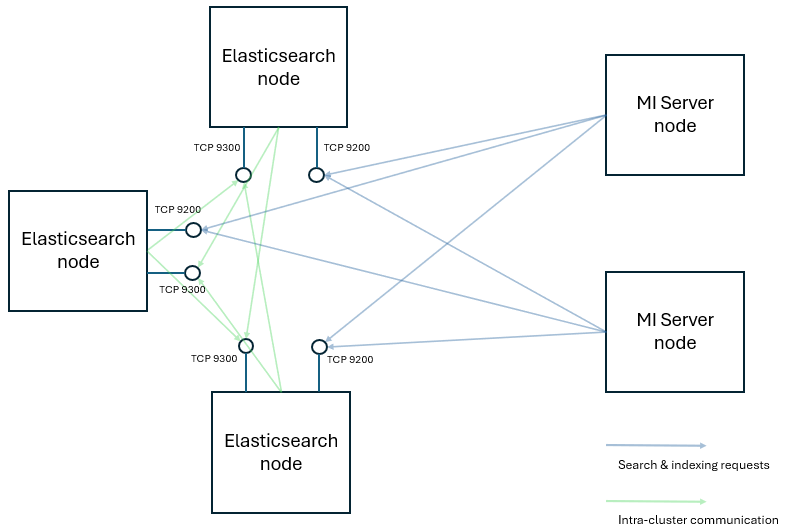
- Elasticsearch uses a consensus algorithm to elect a master node, which is responsible for cluster management tasks such as creating or deleting indices and tracking the health of nodes.
- In a two-node cluster, if one node fails or becomes unreachable, the remaining node cannot form a majority (quorum) to elect itself as master.
- In some scenarios, the remaining node can still respond to queries but the cluster will often become unavailable for read and write operations until the failed node is restored, leading to downtime.
We do not recommend the extra IT burden of setting up data-tiers in the Elasticsearch cluster.
Recommended node roles
An Elasticsearch cluster requires at least one master-eligible node (has the
master role) and at least one data node (has the
data or data_content role if not using data
tiering).
We recommend you do not specify node.roles in
elasticsearch.yml. If you don’t set
node.roles, the node is assigned the following roles by
default:
master*datadata_content*data_hotdata_warmdata_colddata_frozeningest*mlremote_cluster_clienttransform
* node roles required for Granta MI
Sample elasticsearch.yml file
The elasticsearch.yml file specifies cluster settings.
An example elasticsearch.yml file is included in the installation package in the Extras directory. This file is pre-populated with some recommended settings that you can use as a starting point when configuring nodes in a self-managed Elasticsearch cluster for use with Granta MI. For information on all configuration settings available to you, see Elasticsearch configuration reference.
Refer to the Elasticsearch configuration reference documentation for further details of all of these settings.